Imagine a sudden, massive system disruption hitting your primary e-commerce application right during peak holiday shopping traffic. The development team insists that the application code works flawlessly on their local machines, while the operations team scrambles to resolve an unexpected memory leak in the production cluster. This classic operational bottleneck highlights the historic disconnect between those who build software and those who maintain it. Fortunately, modern enterprises solve this exact friction point by leveraging integrated operational frameworks to ensure systemic resilience.
Modern software delivery demands unprecedented scale, velocity, and reliability. Traditional workflows simply cannot keep pace with frequent deployment cycles and complex cloud architectures. Therefore, teams require a holistic methodology that treats infrastructure as an engineering problem rather than a manual administrative chore. By unifying development practices with operational guardrails, organizations can scale their digital services smoothly without sacrificing uptime.
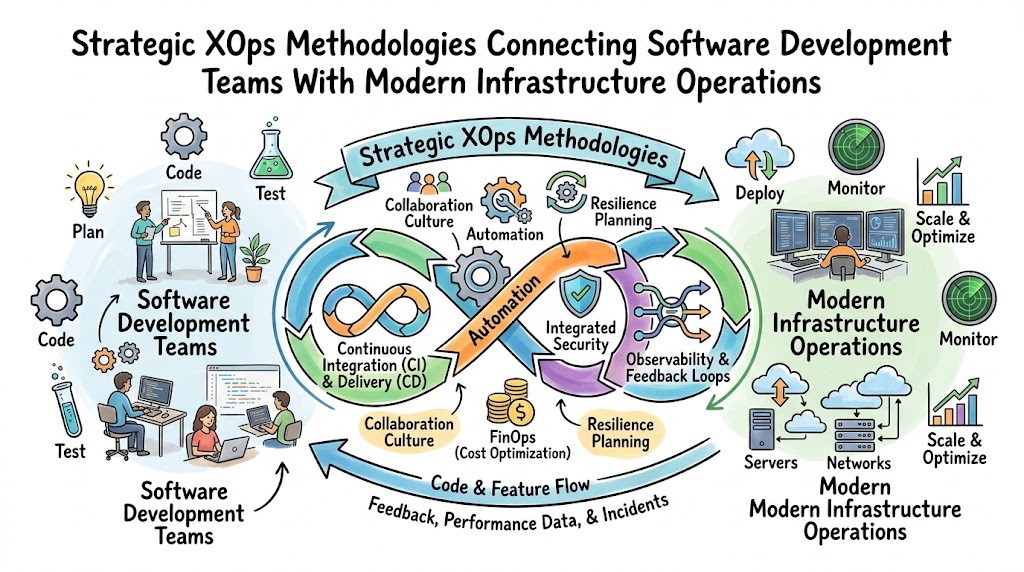
This ultimate guide explores the fundamental architecture, core principles, and strategic real-world applications of advanced operational workflows. You will discover how leading engineering organizations eliminate repetitive toil, establish objective metrics, and design highly available systems. Additionally, we will examine the critical tools and cultural shifts necessary to build a sustainable engineering environment.
To successfully navigate this cultural and technical transformation, professionals must master modern orchestration and observability tools. You can accelerate your engineering journey and build production-ready skills by engaging with the comprehensive resource catalog at Xopsschool. Let us dive deep into the mechanics of bridging the delivery gap.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
During the early eras of enterprise computing, companies separated software creation from hardware administration. Developers focused entirely on writing code and shipping new application features as quickly as possible. Conversely, system administrators shouldered the heavy burden of keeping physical servers running inside corporate data centers.
This sharp division of labor created conflicting incentives and deep organizational silos. Developers wanted to push changes rapidly, whereas operations teams resisted updates to avoid destabilizing the environment. Consequently, deployments occurred infrequently, required massive manual intervention, and often resulted in prolonged system outages.
Moving Toward Unified Workflow Automation
The rise of virtualization and cloud computing fundamentally altered how businesses viewed infrastructure resources. Hardware turned into software, allowing engineers to provision environments instantly through application programming interfaces. As a result, pioneering teams realized that infrastructure management needed to adopt core software development methodologies.
Breaking down these old silos allowed organizations to unify their delivery pipelines through automation. Version control systems began managing infrastructure configurations alongside traditional application source code. This significant shift dramatically reduced human error, accelerated deployment speeds, and established repeatable deployment workflows across entire companies.
Global Expansion Across Commercial Ecosystems
As the benefits of unified workflows became undeniable, these operational frameworks spread across modern large-scale tech enterprises. Global web giants demonstrated that automating infrastructure was the only viable way to manage millions of concurrent user requests. Soon after, traditional commercial ecosystems recognized that digital resilience directly influenced business profitability.
Today, this collaborative approach has expanded far beyond basic automation scripts. It represents a mature corporate strategy adopted by financial institutions, healthcare networks, and global SaaS providers alike. These industries utilize standardized operational frameworks to maintain a competitive edge in a fast-moving marketplace.
Defining Strategic Operations Management
The Core Operational Structure
At its core, strategic operations management applies disciplined software engineering principles to solve complex infrastructure challenges. Instead of relying on manual configuration, teams treat operations as an active software development project. This structure relies on a continuous feedback loop where metrics dictate deployment choices.
Data flows smoothly from running applications back into the development lifecycle through centralized aggregation. This architecture ensures that both builders and operators maintain a shared understanding of system health. Consequently, organizations can detect anomalies and optimize performance bottlenecks long before they impact end users.
Daily Tasks of Systems Coordinators
Systems coordinators and site reliability engineers spend their days balancing engineering projects with operational support duties. They write clean automation scripts, configure monitoring dashboards, and optimize continuous deployment workflows. Additionally, these specialists actively participate in architectural design reviews to ensure new services scale efficiently.
A substantial portion of their daily routine involves identifying architectural weaknesses and building self-healing software mechanisms. When an unexpected incident occurs, they act as frontline responders to mitigate the outage quickly. Afterward, they pivot back to engineering projects that prevent the same issue from happening again.
Localized Control vs. Broad System Architecture
Managing modern systems requires balancing localized component tracking with broad, multi-system architectural oversight. Localized control focuses on individual microservices, isolated databases, or specific container workloads. Engineers monitoring at this level ensure that specific application nodes operate within safe performance parameters.
In contrast, broad system architecture demands a bird’s-eye view of the entire interconnected corporate ecosystem. Specialists must understand how data moves across different cloud regions, third-party APIs, and networking layers. Balancing both perspectives ensures that small component updates do not inadvertently trigger massive systemic failures downstream.
The Efficiency Mindset
Transitioning to modern operational frameworks requires a profound cultural shift toward an efficiency mindset. Teams must reject the outdated notion that system maintenance is a purely reactive, firefighting activity. Instead, they prioritize long-term stability, automated remediation, and proactive architecture optimization over quick manual fixes.
This mindset encourages engineers to view every system failure as an exciting opportunity to improve the software platform. By valuing sustainable engineering over temporary patches, organizations foster a culture of continuous learning. Ultimately, this approach protects engineering velocity while ensuring an exceptionally reliable user experience.
The 7 Core Principles of XOps
1. Embracing Risk and Managing Variability
An essential truth of modern complex infrastructure is that digital components will eventually fail. Attempting to achieve absolute perfection or zero downtime is both prohibitively expensive and logistically impossible. Therefore, engineering teams must learn to embrace inherent risk and manage systemic variability constructively.
Instead of hiding from failure, organizations define acceptable levels of operational risk based on customer requirements. This realistic perspective allows teams to continue shipping innovative features without getting paralyzed by the fear of potential outages. Managing risk logically ensures that development velocity remains high while system stability stays within safe boundaries.
2. Establishing Service Level Objectives (SLOs)
To manage risk effectively, modern teams must establish clear, measurable targets for systemic success known as Service Level Objectives. These targets serve as the ultimate truth for balancing feature development with reliability engineering. They prevent subjective debates between departments regarding system performance and stability.
Engineers derive these objectives from real-world user expectations to ensure relevance. If a system meets its quantitative objectives, developers can comfortably focus on shipping new product features. However, if performance dips below the agreed objective, the team shifts resources toward stabilizing the infrastructure.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, manual, and administrative work that keeps a system running but adds no enduring value. Examples include manually restarting stuck servers, running repetitive database cleanups, or handling routine user access requests. Left unchecked, heavy toil drains engineering morale and severely blocks corporate innovation.
Modern operational principles dictate that teams must actively identify, measure, and engineer away this manual burden. Teams aim to cap operational toil at a fixed percentage of their working hours, usually below half their time. The remaining hours are strictly dedicated to meaningful project engineering that permanently eliminates repetitive tasks.
4. Monitoring & Observability Across the Pipeline
Comprehensive visibility across the entire operational environment prevents dangerous blind spots from threatening system health. Teams must implement deep telemetry that tracks system behavior from code commit all the way to production delivery. This requires collecting granular metrics, structured application logs, and distributed request traces.
[Code Commit] ---> [Build & Test] ---> [Deployment] ---> [Production Telemetry]
^ |
|_______________________ Continuous Feedback ____________________|
Observability allows engineers to answer complex questions about why a system is behaving abnormally in real time. Instead of merely alerting when something breaks, good observability helps engineers understand root causes within highly distributed environments. This deep understanding significantly reduces troubleshooting times during critical incidents.
5. Automation Over Manual Coordination
Scaling modern enterprise workflows requires replacing human coordination with smart, programmatic software solutions. Manual system configurations, manual approvals, and human-driven deployments slow down business agility and introduce human error. Therefore, engineering teams treat infrastructure creation as software code that executes automatically.
Automation ensures that every environment, from staging to production, remains perfectly consistent and easily reproducible. When workloads increase suddenly, automated scaling policies provision extra cloud infrastructure without requiring manual approval. This strategic reliance on software automation allows small teams to manage massive infrastructure footprints effortlessly.
6. Release Engineering and Deployment Stability
Release engineering focuses on building consistent, predictable, and exceptionally safe application delivery pipelines. Teams utilize automated testing frameworks to validate code quality before it ever reaches production environments. This strategy prevents broken code from impacting real users.
Furthermore, modern deployment strategies like canary releases and blue-green deployments minimize operational risk. These techniques allow teams to roll out new features to a tiny fraction of users initially. If the telemetry data shows stable performance, the deployment automatically expands until it covers the entire infrastructure.
7. Simplicity in Network Architecture
As systems expand, unnecessary architectural complexity becomes a primary catalyst for unexpected system failures. Intricate networking configurations, redundant software layers, and overly custom configurations make systems incredibly difficult to troubleshoot. Therefore, modern operational frameworks champion simplicity as a core design requirement.
Keeping environments clean, modular, and minimal directly reduces the overall systemic failure surface area. Engineers should design straightforward data paths and utilize standardized cloud design patterns wherever possible. A simple, elegant system architecture is inherently easier to monitor, maintain, automate, and recover during an outage.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Navigating modern operations requires understanding the precise definitions and practical differences between critical reliability metrics. These terms form the foundation of data-driven system management.
- Service Level Agreement (SLA): The formal, legally binding contract between a service provider and end users defining penalties for underperformance.
- Service Level Objective (SLO): The internal, targeted target goal for system reliability that teams strive to achieve.
- Service Level Indicator (SLI): The precise, quantitative measurement of real-time performance, such as request latency or error rates.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or system instability that an organization is willing to tolerate. It is the mathematical inverse of the established Service Level Objective. For example, if a service commits to a 99% uptime SLO, it possesses a 1% error budget.
This concept changes the game by turning reliability into a currency that teams can actively spend. Developers use this budget to launch innovative features rapidly or experiment with architectural changes. However, if the error budget burns out completely, all feature releases stop, and the entire team focuses on stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as a silent productivity killer that slowly degrades engineering velocity and creates massive operational debt. It encompasses any administrative task that is repetitive, easily automatable, tactical, and lacks long-term value. If your engineering team spends most of their time manually responding to alerts, innovation completely stalls.
To eliminate this burden, teams must carefully track how engineers spend their daily working hours. Once a repetitive manual task is identified, engineers write software scripts to handle it automatically. Systematically eliminating toil ensures that human intelligence is saved for complex architectural engineering challenges.
Incident Management & Postmortems
When severe system outages occur, having a well-defined incident management process prevents chaotic responses. Teams assign clear operational roles, such as an incident commander, to coordinate mitigation efforts efficiently. Communication channels remain organized, ensuring that stakeholders receive timely updates without distracting the engineers solving the issue.
Once the system recovers fully, teams conduct a blameless postmortem to analyze the root cause deeply. A blameless culture assumes that engineers acted with good intentions based on the information they had. The goal is to identify systemic software flaws rather than pointing fingers at human mistakes.
Capacity Planning
Capacity planning is the proactive process of forecasting business growth and preparing underlying infrastructure ahead of demand spikes. Teams must analyze historical telemetry trends to predict future compute, storage, and networking requirements. This ensures that resources remain available during high-traffic enterprise events.
Modern cloud computing simplifies this process through dynamic, rule-based auto-scaling capabilities. However, strategic capacity planning still requires human oversight to optimize cloud spend and manage budget limits. Proper planning prevents unexpected cloud billing surprises while maintaining peak application performance.
The Four Golden Signals of Pipeline Performance
To maintain comprehensive visibility, engineering teams must closely monitor the four golden signals of distributed systems. These metrics offer an immediate, accurate assessment of overall infrastructure health.
| Golden Signal | Technical Focus and Description | Primary Impact Area |
| Latency | The exact time it takes to service a specific system request successfully. | User Experience |
| Traffic | The total demand being placed on the system, measured in requests per second. | Capacity Planning |
| Errors | The rate of incoming requests that fail to resolve successfully. | System Stability |
| Saturation | The overall measure of system resource utilization, such as memory usage. | Resource Efficiency |
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Organizations frequently confuse technical platform implementations with high-level cultural frameworks when transforming their operations. The philosophical difference lies in how a company approaches problem-solving. Culture represents the shared values, communication habits, and blameless mindsets that unite development and operations departments.
On the other hand, platform implementation involves the specific technical tooling, automated pipelines, and cloud environments that enable execution. A company can deploy the most advanced Kubernetes clusters and observability suites available today. However, if the engineering culture remains deeply siloed and blame-driven, operational transformation will ultimately fail.
Roles & Responsibilities Compared
Understanding how day-to-day duties shift between different engineering paradigms helps organizations structure their teams effectively. Each approach brings a unique focus to the delivery lifecycle.
- Cultural Framework Focus: Fosters shared organizational responsibility, breaks down department communication barriers, and emphasizes empathy across teams.
- Platform Implementation Focus: Builds self-service developer platforms, provisions automated infrastructure, and configures centralized monitoring tools.
- Daily Dev Operations Role: Manages continuous integration pipelines, writes deployment automation scripts, and supports application release cycles.
- Site Reliability Engineering Role: Writes production-grade software to optimize system reliability, manages error budgets, and orchestrates incident mitigation.
Can You Have Both Disciplines?
Modern enterprises do not have to choose between cultural frameworks and technical platform implementations. In fact, these separate engineering philosophies coexist beautifully and actively support each other in mature organizations. A healthy culture creates the psychological safety needed to build robust, automated platform solutions.
Simultaneously, a well-engineered self-service platform reduces cognitive load on developers, making it easier to adopt cultural practices. The platform serves as the practical implementation of the team’s shared operational values. Merging both disciplines allows businesses to achieve high deployment velocities alongside exceptional system uptime.
Which One Should Your Team Adopt?
Choosing the right operational focus depends heavily on your organizational size, engineering maturity, and immediate business challenges. Small startups with simple application architectures should prioritize establishing a collaborative, flexible culture first. At this early stage, heavy automated platform investments often introduce unnecessary overhead.
Conversely, large enterprises managing hundreds of microservices must invest heavily in standardized platform implementations. Without centralized platforms, large development teams will waste valuable time re-inventing separate infrastructure solutions. Evaluate your current operational bottlenecks to determine whether you need a cultural shift or technical tooling.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major software enterprises rely on precise operational metrics to drive business decisions and maintain system health. These industry leaders do not guess whether their applications are performing well for global users. Instead, they aggregate billions of telemetry data points daily into centralized streaming dashboards.
By analyzing real-time indicators, tech leaders can automatically trigger infrastructure adjustments before users experience any visible slow downs. This data-driven approach also guides product roadmap priorities. If the data shows that a core service is consuming its error budget, product managers pause feature additions to focus on architectural hardening.
Chaos Engineering Approaches to Resilient Systems
Top-tier engineering organizations do not wait for unexpected production outages to test their incident response capabilities. Instead, they practice chaos engineering, which involves intentionally injecting controlled failures into live production environments. This proactive approach uncovers hidden architectural flaws before they cause widespread user disruption.
Engineers might randomly terminate server instances, inject artificial network latency, or simulate database disconnects during regular working hours. These experiments validate that the system’s automated self-healing mechanisms function correctly under duress. Furthermore, chaos engineering gives response teams valuable practice handling real-world failure scenarios safely.
Handling Reliability at Massive Scale
Managing highly distributed microservices handling millions of concurrent global transactions requires an advanced architectural strategy. Traditional monolithic architectures collapse under this level of demand. Modern enterprises solve this by breaking applications into small, isolated services that scale independently.
These systems utilize advanced traffic routing, distributed caching layers, and asynchronous messaging queues to balance massive workloads. If a single microservice experiences a failure, circuit-breaker patterns isolate the issue immediately. This isolation prevents a localized component error from cascading into a catastrophic, company-wide system outage.
High-Availability in Fintech Operations
Financial technology and payment processing platforms operate under a strict zero-tolerance requirement for application downtime. A single minute of systemic unavailability can result in millions of dollars in lost revenue and severe regulatory penalties. Therefore, fintech operations utilize multi-region, active-active cloud architectures to guarantee continuous availability.
[Global Traffic Router]
/ \
[Cloud Region A: Active] [Cloud Region B: Active]
| \ / |
[Database Replica] <--- [Real-Time Sync] ---> [Database Replica]
Data is replicated synchronously across physically isolated geographic regions in real time. If a natural disaster takes an entire cloud data center offline, traffic redirects instantly to the surviving region. This rigorous architecture ensures that consumer financial transactions process smoothly without interruption, regardless of background infrastructure issues.
Scaled-Down but Essential Systems for Startups
Early-stage startups often assume that robust operational frameworks are only necessary for massive enterprise tech giants. However, small teams can apply these core principles efficiently without taking on heavy engineering overhead. Startups utilize managed cloud services and all-in-one observability platforms to keep operations lean.
By defining basic Service Level Objectives and automating their deployment pipelines early on, startups avoid accumulating massive technical debt. This upfront operational discipline allows small engineering teams to scale their products rapidly as customer demand grows. Ultimately, clean operations prevent early-stage companies from getting bogged down by constant firefighting.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A frequent mistake companies make is believing that modern operations simply means assigning developers to a rotating on-call schedule. True operational engineering is a proactive discipline focused on writing software to prevent incidents entirely. It is not merely about answering pager alerts in the middle of the night.
When a team treats operations as a purely reactive on-call duty, engineers quickly become exhausted and burned out. If responders only patch symptoms without fixing underlying root causes, system reliability will continuously degrade over time. Organizations must dedicate significant engineering time to building long-term systemic fixes.
Mistake 2 — Setting Unrealistic SLOs
In an effort to impress customers, business leaders often demand perfect 100% uptime goals for their applications. However, chasing an unrealistic Service Level Objective stalls feature innovation and burns through valuable engineering resources. Achieving incremental gains in uptime requires exponential increases in architectural cost and complexity.
Setting an overly strict objective means the team’s error budget will constantly remain empty. Consequently, developers are forced to repeatedly pause product feature releases to fix minor performance variances. Organizations must set realistic objectives that balance the actual needs of users with engineering agility.
Mistake 3 — Ignoring Toil Until It’s Too Late
When engineering teams rush to meet aggressive product deadlines, they frequently neglect routine operational maintenance. Manual database scripts, manual server cleanups, and human-driven deployments are ignored as minor inconveniences initially. However, as the infrastructure expands, this accumulated manual toil grows exponentially.
Eventually, the burden of manual tasks consumes the team’s entire working week, leaving zero time for actual engineering project work. This state of operational debt completely blocks innovation and causes major project delays. Teams must systematically measure and automate toil continuously to maintain development velocity.
Mistake 4 — Skipping Blameless Postmortems
When a major system outage occurs, human nature often drives teams to look for someone to blame. Punishing the individual engineer who typed a wrong command creates a toxic culture of fear across the company. As a result, engineers begin hiding system mistakes and avoiding taking risks.
Skipping blameless postmortems prevents organizations from discovering the true systemic flaws that allowed the human error to occur. A robust infrastructure should be designed to survive a single incorrect command or typos safely. Examining failures without assigning blame is the only way to build resilient corporate platforms.
Mistake 5 — Monitoring Without Actionable Alerts
Configuring alerts for every single metric and system notification creates a dangerous environment of severe alert fatigue. If an engineer’s pager goes off repeatedly for non-critical warnings, they will eventually start ignoring notifications. This desensitization leads to real, catastrophic outages getting missed during the noise.
Every alert configured in your observability pipeline must be meaningful, urgent, and require direct human action to resolve. If an issue does not require immediate intervention, it belongs in an email summary or a non-urgent dashboard. Keeping alerts strictly actionable protects engineer sanity and ensures rapid response times.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Many organizations continue to follow an outdated model where developers design an application completely before throwing it over the wall. When operational specialists are excluded from early design phases, they inherit architectures that are incredibly difficult to deploy. This disconnect leads to severe performance problems later on.
Operational input is critical from day one to evaluate system scalability, monitoring needs, and failure recovery paths. Bringing infrastructure specialists into early architectural discussions ensures that applications are optimized for production realities. This collaborative design approach prevents expensive re-engineering work after a product launches.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining a healthy production environment requires a robust suite of modern monitoring and observability platforms. These technologies ingest telemetry data across your entire software delivery pipeline.
| Tool Name | Core Purpose | Key Strengths |
| Prometheus | Time-series metric collection | Exceptionally powerful alerting and multi-dimensional data model |
| Grafana | Centralized metric visualization | Beautiful, customizable dashboards that connect to multiple data sources |
| Datadog | Unified SaaS observability | Seamless integration across logs, traces, and infrastructure metrics |
| New Relic | Full-stack performance analysis | Deep application performance monitoring and user experience tracking |
Incident Management
When unexpected downtime strikes, incident management platforms organize your team’s communication and response workflows. These systems route alerts to the correct on-call engineer instantly based on predefined schedules. They keep emergency responses structured, preventing chaotic troubleshooting sessions.
PagerDuty serves as an industry standard for intelligent alerting and incident response orchestration across global teams. It integrates smoothly with monitoring suites to turn anomalies into actionable notifications immediately. Utilizing these platforms ensures that critical incidents are mitigated rapidly, minimizing overall business disruption.
CI/CD & Release Engineering
Automated continuous integration and continuous delivery engines form the backbone of modern release engineering. These systems automatically pull code changes, run automated tests, and deploy packages directly to target cloud environments. They ensure that delivery processes remain perfectly consistent.
Jenkins remains a widely adopted automation engine due to its massive ecosystem of customizable plugins. Meanwhile, GitOps controllers like Argo CD and advanced CD platforms like Spinnaker handle declarative Kubernetes deployments flawlessly. These tools allow teams to execute automated canary rollouts and safe infrastructure updates with high confidence.
Chaos Engineering
Building truly resilient infrastructure requires specialized tools designed to inject controlled failures into production environments safely. These tools help teams validate their system’s automated recovery mechanisms before actual disasters occur. They turn hypothetical architectural weaknesses into concrete engineering insights.
Chaos Monkey, originally created by Netflix, randomly terminates cloud instances to ensure systems handle infrastructure loss gracefully. Modern chaos platforms allow teams to simulate complex network splits, resource saturation, and database outages easily. Practicing controlled failures regularly ensures that your production environment remains inherently resilient.
SLO Management
As Service Level Objectives become central to business operations, specialized platforms have emerged to track reliability metrics explicitly. These tools integrate with existing monitoring setups to calculate real-time error budget consumption rates automatically. They bridge the gap between high-level business goals and low-level technical metrics.
Nobl9 stands out as a dedicated platform designed specifically for managing corporate SLOs and error budgets cleanly. It helps product and engineering managers define clear reliability targets and alerts teams before budgets burn out completely. Utilizing dedicated management tools keeps entire organizations aligned around quantifiable user satisfaction metrics.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Starting a career in modern operations engineering requires mastering a blend of software development and systems administration skills. You must feel completely comfortable navigating the Linux terminal and managing operating system resources. Additionally, you need to learn a programming language like Python or Go to write clean automation scripts.
Understanding core networking concepts, including DNS, load balancing, and HTTP protocols, is absolutely essential for troubleshooting distributed environments. From there, you must master infrastructure-as-code concepts using tools like Terraform to provision cloud infrastructure programmatically. Finally, learn how containerized workloads function using Docker and Kubernetes orchestration.
The Professional Learning Path
The roadmap to becoming a senior infrastructure specialist follows a clear, step-by-step educational progression. Begin by learning how to configure and deploy a basic web application manually on a single virtual server. Once you master the basics, focus on writing scripts to automate that entire configuration process end-to-end.
[Systems Basics] ---> [Automation Scripting] ---> [Cloud & Containers] ---> [Senior Architecture]
Next, transition into cloud-native architectures by learning how to manage containerized microservices across public cloud platforms. Focus on implementing comprehensive monitoring, log aggregation, and alerting pipelines for those distributed applications. Advanced stages of the path involve designing multi-region disaster recovery strategies, managing massive error budgets, and leading blameless postmortem cultures.
Certifications Worth Pursuing
Industry-recognized certifications are an excellent way to validate your infrastructure expertise and stand out to enterprise recruiters. Earning credentials demonstrates a structured commitment to mastering complex technical ecosystems.
- Certified Kubernetes Administrator (CKA): Validates your practical ability to configure, manage, and troubleshoot production Kubernetes clusters.
- AWS Certified DevOps Engineer — Professional: Confirms technical expertise in automating, provisioning, and managing secure distributed systems on AWS.
- Google Cloud Professional Cloud DevOps Engineer: Measures your proficiency in balancing service reliability with feature delivery velocity on Google Cloud.
Educational Resources with XOps School
Navigating this vast technical landscape on your own can feel incredibly overwhelming given how fast tools evolve. To streamline your learning process, it is highly beneficial to follow a structured curriculum designed by real-world industry mentors. You can find comprehensive deep-dives, hands-on labs, and expert material by visiting Xopsschool.
Following an expert-led learning framework ensures that you spend your time focused on the skills that matter most to modern companies. You will gain practical experience configuring production observability, managing CI/CD automation, and implementing advanced error budgets. Investing in structured education is the fastest way to transition from a traditional administrator to an operations expert.
The Future of Systems Management
AI and Automation in System Optimization
The integration of machine learning intelligence into infrastructure management is rapidly transforming how companies maintain system health. Automated systems can now analyze millions of historical telemetry logs in real time to detect complex anomaly patterns. This capability allows teams to catch emerging infrastructure issues long before traditional static alerts trigger.
Furthermore, machine learning speeds up root cause analysis during critical system outages by automatically correlating disparate telemetry points. In the future, automated platforms will move beyond basic alerting to handle intelligent, self-healing remediation completely. This evolution allows human engineers to step away from troubleshooting and focus entirely on high-level architectural design.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents the next major evolutionary step in the modernization of corporate infrastructure delivery. Instead of forcing every developer to understand complex cloud configurations, specialized teams build Internal Developer Platforms (IDPs). These platforms provide curated, automated, self-service portals that developers use to ship code independently.
This shift significantly reduces cognitive load on software builders, allowing them to focus on writing application code. Platform engineering packages complex networking, security compliance, and deployment pipelines into simple, repeatable templates. Consequently, organizations achieve incredible deployment velocity while ensuring that strict operational guardrails remain automatically enforced.
Management in Cloud-Native & Kubernetes Environments
As organizations migrate their core workloads into dynamic containerized clusters, traditional server management practices become obsolete. Kubernetes has become the standard operating system of the modern cloud, but it introduces unique configuration challenges. Managing ephemeral microservices that spin up and down constantly requires advanced orchestration expertise.
Future operational frameworks must adapt to handle complex service mesh networks, dynamic resource allocations, and decentralized security policies. Engineers must design infrastructure that treats compute instances as completely disposable assets. Mastering container orchestration remains a non-negotiable requirement for sustaining highly available modern software architectures.
Operational Skills That Will Matter Most
As basic infrastructure provisioning becomes fully automated, the role of the systems specialist will continue to shift upstream. Financial cost optimization, often called FinOps, is becoming a critical skill as businesses look to manage rising cloud expenditures. Engineers must learn to design architectures that are both highly resilient and exceptionally cost-effective.
Additionally, deep data observability and cross-cloud data tracing will matter immensely as enterprise ecosystems grow more distributed. Developing a deep understanding of data privacy laws and automated security compliance integration will also elevate your professional engineering value. Cultivating these advanced operational skills ensures you remain highly sought after in an evolving corporate marketplace.
FAQ Section
- What is the standard career path for an infrastructure operations engineer?
Professionals typically begin their journey as junior systems administrators, cloud support engineers, or software developers. Over time, they build deep skills in scripting, deployment automation, container orchestration, and full-stack observability. This technical progression allows them to step into specialized roles like DevOps engineers, site reliability engineers, or enterprise platform architects. - How does site reliability engineering differ from traditional IT operations?
Traditional IT operations rely heavily on manual configurations, reactive troubleshooting, and siloed administrative workflows. In stark contrast, site reliability engineering treats infrastructure explicitly as a software problem by applying disciplined engineering practices. This modern approach focuses heavily on automation, proactive architectural design, and utilizing objective data metrics to drive systemic stability. - What are the average salary trends for specialists in this domain?
Due to the critical role digital uptime plays in business profitability, skilled operations engineers command exceptional market compensation. Globally, mid-level professionals earn highly competitive salaries, while senior architects and principal platform engineers frequently rank among the top earners in technology. This strong financial demand continues to grow as traditional industries accelerate their cloud modernization initiatives. - How do teams accurately calculate an error budget for a service?
An error budget is calculated mathematically as the inverse of an established, user-focused Service Level Objective. For example, if a microservice sets an internal uptime target of 99.9% for incoming traffic over a thirty-day window, its remaining allowable failure rate is exactly 0.1%. This percentage translates into a precise number of minutes that the service can experience safe degradation. - Why is a blameless culture necessary for successful infrastructure management?
When a company culture focuses on blaming individuals for system outages, engineers naturally hide mistakes and avoid technical innovation. A blameless approach shifts the focus toward identifying the underlying software flaws and systemic gaps that allowed the human error to impact production. This transparency allows the entire organization to learn from failures and build permanently resilient platforms. - Can small startups benefit from implementing advanced operational frameworks?
Yes, early-stage startups benefit immensely by adopting core operational principles like deployment automation and clear Service Level Objectives early on. Implementing lean automation prevents small development teams from accumulating massive technical debt and getting bogged down by constant manual firefighting. This foundational discipline allows startups to scale their products rapidly and smoothly as user demand increases.
Final Summary
Sustaining high-performing, resilient modern infrastructure requires moving far beyond manual configurations and reactive firefighting habits. True operational excellence is achieved by treating infrastructure as a software problem, eliminating repetitive manual toil, and establishing objective data metrics. By implementing disciplined operational frameworks and cultivating a blameless culture, organizations balance high deployment velocity with exceptional system uptime. Embracing continuous automation and deep observability ensures your business remains competitive in an evolving marketplace. Professionals who master these core frameworks will continue to shape the future of digital product delivery. Start mastering these critical performance frameworks today by expanding your technical skills with the expert-led learning paths available at [Xopsschool].