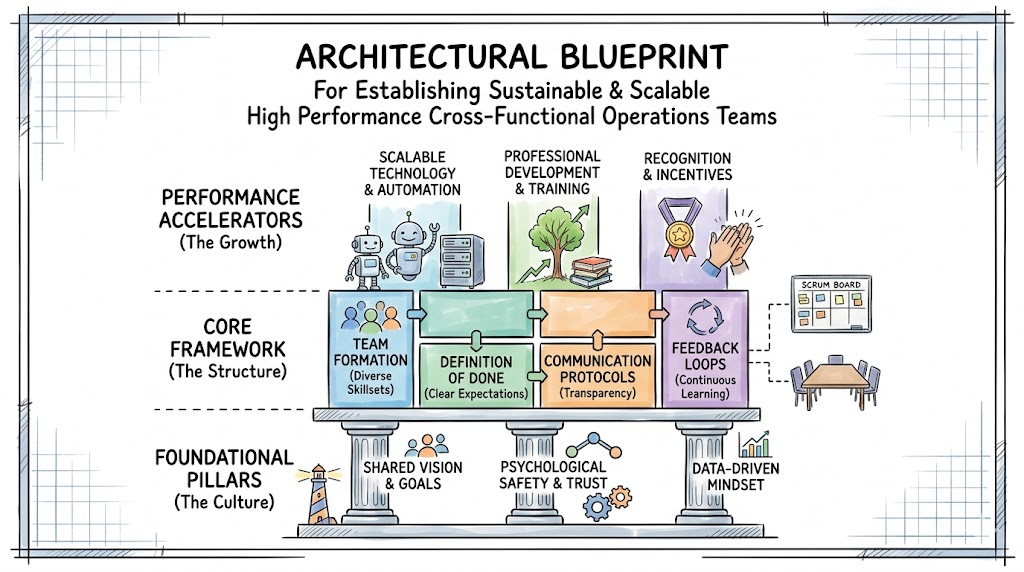
Detailed Analysis of the Operational Framework
A sudden, catastrophic database deadlock brings your primary transactional database cluster down during peak traffic hours. While customers face frustrating payment timeouts, your development team points fingers at the cloud infrastructure engineers. Concurrently, the infrastructure team blames the application developers for pushing unoptimized database queries. This exact operational bottleneck compromises customer satisfaction, drains engineering energy, and highlights a fundamental lack of systemic alignment. Consequently, modern tech organizations require a unified strategy that breaks down technical silos and builds bridges between isolated operations.
Building a successful XOps team directly addresses this universal bottleneck by embedding operational intelligence right into every single phase of your development lifecycle. Essentially, XOps represents the cross-functional convergence of diverse operational disciplines, including DevOps, DataOps, MLOps, GitOps, and FinOps, into a single cohesive delivery strategy. This modern operational framework treats infrastructure, data integration, machine learning pipelines, and financial optimization as code-driven, highly automated workflows. Because digital platforms now scale exponentially, organizations must move away from manually managed systems and fully embrace automated, cross-functional orchestration.
This comprehensive guide covers everything you need to know about designing, scaling, and maintaining a high-performing cross-functional operations team. We will explore historical engineering bottlenecks, define strategic infrastructure management, analyze core deployment principles, and break down critical tracking metrics. Furthermore, this guide clarifies the specific structural differences between high-level engineering cultures and technical platform implementations. We also address common industry mistakes, outline an actionable career roadmap for specialists, and examine the future of automated infrastructure.
To help your business successfully navigate this transformation, discovering expert guidance and structured architectural workflows remains highly critical. You can master these advanced operational strategies and build highly resilient engineering structures by joining the professional community at Xopsschool. Let us dive deep into the specific historical shifts that caused the rise of this cross-functional movement.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
During the early days of corporate computing, software development and system administration operated in completely isolated universes. Developers focused exclusively on writing new features, while system administrators manually configured bare-metal servers inside local data centers. Because these groups maintained entirely separate priorities, a massive wall of confusion naturally developed between them.
Developers consistently pushed for rapid application changes, whereas administrators strictly prioritized system uptime by resisting changes. This fundamental misalignment forced engineers to pass manual deployment files over the wall through clumsy ticketing systems. Consequently, deployments frequently failed, debugging took days, and corporate infrastructure remained highly fragile and unpredictable.
Moving Toward Unified Workflow Automation
As virtualization technologies and public cloud infrastructure arrived, the traditional method of manually configuring servers quickly became completely unsustainable. Organizations rapidly realized that software velocity mattered little if the underlying infrastructure took weeks to provision manually.
+-------------------+ Manual Ticketing +-------------------+
| Development Team | -----------------------------> | Operations Team |
| (Focus: Speed) | <----------------------------- | (Focus: Uptime) |
+-------------------+ Siloed Hand-offs +-------------------+
This realization sparked a major movement toward unified workflow automation, treating infrastructure setup exactly like software application code. By breaking down ancient organizational silos, engineers began creating automated pipelines that combined development and operations into a single continuous workflow. This structural shift allowed teams to ship software updates much faster while maintaining high operational stability.
Global Expansion Across Commercial Ecosystems
What started as an internal experimental workflow inside pioneering web enterprises quickly expanded across global commercial ecosystems. Tech giants proved that managing massive distributed applications required a completely programmatic approach to system stability.
Soon, traditional enterprises, financial institutions, and retail conglomerates noticed these immense operational velocity gains. They rapidly adopted these automated frameworks to remain competitive in an increasingly digital marketplace. Today, cross-functional operational excellence is no longer a luxury but a core requirement for any enterprise seeking global scale.
Defining Strategic Operations Management
The Core Operational Structure
The underlying architecture of modern operations management revolves around a continuous feedback loop of telemetry, automation, and iterative optimization. Data flows continuously from live production systems back into engineering pipelines, enabling proactive systemic updates.
+-------------------------------------------------------+
| |
v |
[Code & Configure] -> [Automate & Deploy] -> [Observe & Monitor]
This structure ensures that teams never make infrastructure changes based on mere guesswork or vague intuition. Instead, every single architectural alteration relies strictly on real-world data collected from active software environments. By unifying configuration management, continuous deployment, and deep observability, organizations build self-healing software platforms that scale automatically.
Daily Tasks of Systems Coordinators
Systems coordinators and cross-functional operations engineers spend their working hours building systems rather than fighting fires manually. They write clean infrastructure-as-code files, design automated testing pipelines, and optimize complex telemetry dashboards.
Additionally, these engineers participate heavily in architectural review meetings to ensure that new application features scale correctly. When a system anomaly occurs, they do not just apply a quick patch to fix the immediate symptom. Instead, they write automated scripts to prevent that specific class of operational failure from ever happening again.
Localized Control vs. Broad System Architecture
Managing modern software environments requires balancing local component tracking against broad, overarching system architecture. Localized control focus looks directly at individual components, such as a single microservice instance or an isolated database table.
Conversely, broad system architecture monitors how thousands of interconnected services communicate across multiple cloud regions. High-performing teams intentionally balance both perspectives by utilizing localized automation that reports into a centralized telemetry framework. This dual approach ensures that small component failures never cascade into catastrophic platform-wide outages.
The Efficiency Mindset
Transitioning to a successful cross-functional operational model demands a profound cultural shift toward an efficiency mindset. This mindset requires engineers to view manual intervention as a severe systemic failure rather than a normal daily duty.
Teams must intentionally prioritize long-term infrastructure stability over short-term feature delivery speed. By treating reliability as a core feature of the product, organizations naturally build a culture of shared operational responsibility. This cultural shift ultimately drives sustained engineering velocity and keeps digital platforms running smoothly around the clock.
The 7 Core Principles of How to Build a Successful XOps Team
1. Embracing Risk and Managing Variability
An absolute truth of modern distributed systems is that software components will eventually fail at some point. Trying to build a completely flawless system that achieves absolute zero downtime is prohibitively expensive and slows innovation.
Therefore, successful teams learn to embrace calculated operational risk by defining acceptable levels of systemic variability. They focus on building highly resilient architectures that handle minor failures gracefully without dropping core customer transactions. By accepting that failure is inevitable, engineers build robust fault-tolerant software structures that protect user workflows.
2. Establishing Service Level Objectives (SLOs)
You cannot manage what you do not accurately measure, which makes defining quantifiable operational targets incredibly important. Teams must establish clear Service Level Objectives that define the exact level of performance your users expect.
These objectives act as a vital mathematical compass, guiding engineering teams on when to push new features or focus on stability. When a platform stays well within its defined objectives, developers can ship risky new updates safely. However, if performance dips below the agreed objective, the entire team shifts focus toward improving system infrastructure.
3. Eliminating Toil and Manual Processes
Toil represents repetitive, manual, operational work that lacks long-term strategic value and scales linearly with system growth. Examples include manually resetting application servers, manually creating user accounts, or manually running database cleanup scripts.
Traditional Ops: Scale Teams Linearly ---> [More Servers = More People]
Modern XOps: Scale Systematically ---> [More Servers = More Automation]
Cross-functional operations teams make it a core priority to identify, measure, and systematically engineer away this manual toil. They limit manual administrative tasks to less than half of an engineer’s daily schedule. The remaining time goes directly toward building automation that permanently eliminates those repetitive processes.
4. Monitoring & Observability Across the Pipeline
Traditional monitoring merely tells you when a specific server stops working by flashing a simple red light on a dashboard. Modern observability goes much deeper by allowing engineers to infer the internal state of a system based on external outputs.
By collecting detailed logs, granular metrics, and distributed request traces across the entire deployment pipeline, teams eliminate operational blind spots. This deep visibility allows engineers to pinpoint complex performance regressions across highly distributed microservice environments. Consequently, teams diagnose root causes in minutes rather than spending long hours guessing where the breakdown occurred.
5. Automation Over Manual Coordination
Scaling modern enterprise workflows requires a deep engineering commitment to software-driven automation over manual human coordination. Whenever a process needs to occur more than twice, engineers must write code to automate that exact sequence.
This approach applies to software deployment, infrastructure provisioning, security compliance auditing, and routine database maintenance tasks. Automated workflows eliminate human typing mistakes, ensure consistent configurations across testing environments, and accelerate deployment speeds. By relying on smart software solutions, your engineering organization scales up its operations without needing to hire an army of administrators.
6. Release Engineering and Deployment Stability
Shipping software updates to a live production environment must become a completely routine, boring, and predictable event. Release engineering focuses on building highly standardized deployment pipelines that test and package code automatically.
Teams utilize advanced strategies like blue-green deployments or canary rollouts to minimize the blast radius of new bugs. These methods allow you to test new code updates on a tiny slice of live user traffic before updating the entire system. If the canary release displays any signs of instability, automated systems immediately roll back the update to protect users.
7. Simplicity in Network Architecture
As software systems expand over time, their underlying infrastructure naturally becomes increasingly complex and difficult to manage. Unnecessary architectural complexity directly introduces hidden failure points, confusing configurations, and difficult debugging scenarios.
Therefore, high-performing operational teams fiercely protect simplicity across their entire network and software environment. They write clean, declarative configurations, use uniform naming conventions, and avoid building bespoke, customized infrastructure pieces. Keeping environments clean and minimal directly reduces your overall failure surface and makes system maintenance straightforward.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Navigating modern system infrastructure requires a crystal-clear understanding of the core metrics that govern platform reliability. These concepts connect technical performance directly to user satisfaction and business agreements.
| Concept | Formal Definition | Target Audience | Practical Example |
| SLA | Service Level Agreement | Legal & Business Teams | A contractual promise guaranteeing 99.9% uptime, or the company refunds money. |
| SLO | Service Level Objective | Engineering & Product Teams | An internal reliability target set at 99.95% to ensure the team beats the SLA. |
| SLI | Service Level Indicator | Operations & DevOps Teams | The precise, real-time measurement of performance, like tracking actual successful API calls. |
- Service Level Agreement (SLA): This is the legal contract your business signs with customers promising a specific level of system availability. Dropping below this boundary carries real financial penalties or contractual credits.
- Service Level Objective (SLO): This represents the internal target your engineering team shoots for to ensure you never breach the official SLA. It acts as a safety buffer that keeps everyone aligned on performance goals.
- Service Level Indicator (SLI): This is the actual quantitative measurement of your system’s performance at any given moment. It calculates the specific percentage of successful requests over a defined time window.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system instability your platform can tolerate before users become unhappy. Mathematically, it is the simple inverse of your Service Level Objective ($100\% – \text{SLO}$). For example, if your team establishes a 99.9% uptime objective, your system possesses a 0.1% error budget.
This budget acts as a clear, data-driven framework that perfectly balances architectural innovation with baseline system safety. Product developers spend this budget by shipping innovative, high-risk features to production rapidly. However, if unexpected outages completely consume the budget, all feature releases halt instantly until operations engineers fix the structural stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as an invisible tax on your engineering velocity, slowly draining team morale and blocking valuable innovation. It consists of administrative tasks that are manual, repetitive, automatable, and lack long-term business value.
To systematically eliminate toil, teams must first track how many hours engineers spend on manual operations each week. If repetitive tasks begin taking up more than 50% of your time, engineering leadership must intervene immediately. Teams calculate the financial cost of this manual work and use that data to justify building automated software solutions.
Incident Management & Postmortems
When a severe operational failure occurs, effective teams shift away from frantic panic into structured, orderly incident management. They assign clear roles, designating an incident commander to run the restoration effort and a communications lead to update stakeholders.
[System Outage] -> [Incident Commander Formed] -> [Symptom Mitigated]
|
[Process Updated] <- [Action Items Tracked] <- [Blameless Postmortem]
Once the system returns to a healthy state, the team conducts a thoroughly detailed, blameless postmortem meeting. This practice operates on the core assumption that engineers make choices with the best information they have at the time. Instead of assessing blame, engineers analyze the systemic flaws that allowed the human mistake to impact production.
Capacity Planning
Capacity planning ensures that your digital platform possesses enough computational resources to handle future business growth safely. Engineers analyze historical traffic patterns, seasonal usage spikes, and upcoming marketing campaigns to forecast infrastructure needs.
Instead of simply throwing expensive hardware at the problem, teams optimize resource consumption through smart software design. They set up automated scaling rules that dynamically adjust computing power based on real-time system demand. This proactive approach prevents sudden resource exhaustion events while simultaneously keeping cloud infrastructure costs under control.
The Four Golden Signals of Pipeline Performance
When building deep observability into complex distributed applications, engineers prioritize tracking four critical performance metrics. These metrics provide a clear, comprehensive view of system health and highlight emerging bottlenecks before they cause outages.
- Latency: The precise time it takes for a system to process a specific request and return a response to the user.
- Traffic: A direct measure of the total demand being placed on the system, such as HTTP requests per second.
- Errors: The rate of requests that fail completely or return unexpected responses across your infrastructure.
- Saturation: A metric showing how close your system resources are to reaching their maximum operating limits, like memory usage.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly believe that purchasing a modern software platform instantly solves their operational challenges. The core difference lies between high-level cultural frameworks and concrete technical platform implementations.
Culture represents the shared mindset, communication patterns, and engineering philosophies that define how humans interact within an organization. A platform implementation, on the other hand, consists of the actual software tools, cloud servers, and automated code pipelines. Buying advanced tools without fixing a toxic, siloed organizational culture never results in high platform reliability.
Roles & Responsibilities Compared
Understanding how different organizational paradigms divide daily work helps teams structure their internal engineering groups effectively. The division of labor influences how quickly code moves from development to production.
- Cultural Framework Groups: Focus heavily on shared responsibility, reducing communication barriers, and aligning business goals across separate teams.
- Platform Engineering Groups: Focus on building reusable internal developer platforms that provide automated self-service infrastructure tools.
- Cross-Functional Operations Groups: Focus directly on managing system availability, engineering away toil, and optimizing production telemetry.
- Product Development Groups: Focus on writing business logic, building application features, and shipping value to end customers.
Can You Have Both Disciplines?
Modern tech enterprises successfully combine cultural engineering frameworks with strong internal platform teams to maximize delivery efficiency. The platform engineering team builds a secure, automated foundation that makes provisioning cloud resources incredibly simple for developers.
Concurrently, the cross-functional operations mindset ensures that these self-service systems stay observable, reliable, and cost-efficient. These separate engineering philosophies do not compete; instead, they actively support each other. This powerful combination allows organizations to scale up their digital infrastructure safely while maintaining high developer velocity.
Which One Should Your Team Adopt?
Deciding where to focus your engineering energy depends directly on your current organizational size and technical maturity. Small startups should prioritize building a strong culture of shared operational responsibility without building complex internal platforms.
As your engineering team grows past fifty developers, investing in a dedicated platform engineering group becomes highly valuable. This team reduces cognitive load on developers by providing standardized, automated infrastructure templates. Ultimately, your organization should aim to blend operational cultural principles with automated platform implementations.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global streaming platforms use granular operational metrics to provide uninterrupted video delivery to hundreds of millions of concurrent users. Their automated delivery systems continuously monitor regional network latency and error rates across diverse internet service providers.
If a specific network path shows signs of degradation, automated traffic routers instantly redirect user streams to healthy data centers. This automated response occurs in milliseconds, ensuring that customers experience seamless playback without seeing a buffering spinner. By relying on real-time telemetry, these businesses maintain exceptional user satisfaction around the world.
Chaos Engineering Approaches to Resilient Systems
Large-scale web platforms intentionally inject controlled failures into their production systems to uncover hidden structural weaknesses. They run specialized software utilities that randomly shut down live application instances during normal business hours.
This practice forces engineers to design applications that handle sudden hardware disappearances completely automatically. If a system fails during a controlled chaos experiment, the team fixes the architectural flaw before it causes an actual emergency. This proactive approach builds immense confidence in the overall resilience of the global infrastructure.
Handling Reliability at Massive Scale
Global e-commerce enterprises experience massive, predictable traffic spikes during major annual holiday shopping events. To survive these immense demand spikes safely, their engineering groups run automated load tests months in advance.
They simulate millions of concurrent customer transactions to see exactly how their microservices behave under extreme pressure. These tests reveal hidden database locks, network bottlenecks, and memory leaks that would otherwise crash the platform. By proactively resolving these issues, their digital storefronts process billions of dollars in sales smoothly without experiencing outages.
High-Availability in Fintech Operations
Digital payment platforms operate inside a strict zero-tolerance environment when it comes to system downtime or data corruption. A single dropped transaction or database synchronization error can trigger severe financial penalties and regulatory audits.
Therefore, financial tech operations teams implement highly synchronized multi-region database architectures that write data to multiple geographic locations simultaneously. They combine this hard infrastructure with continuous real-time fraud detection pipelines that analyze transaction patterns instantaneously. This meticulous focus on high availability ensures that customer money moves securely and reliably at any hour of the day.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not possess the massive engineering budgets or large teams that global tech conglomerates command. However, they still apply core operational principles efficiently by leveraging managed cloud services and lightweight automation tools.
Instead of building bespoke infrastructure, they use managed container platforms and simple, pre-built continuous deployment pipelines. They set up basic, actionable alerts on core business metrics like API response success rates and database disk usage. This lightweight setup protects their early customer base while allowing the small team to focus on building features.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many traditional corporate leaders mistakenly believe they have successfully adopted a modern operational model by simply handing out cell phones to developers. They treat the engineering discipline as a glorified 24/7 on-call rotation focused entirely on reactive firefighting.
This approach completely misses the point of cross-functional operations, which centers on proactive software engineering. If your engineers spend all their time responding to repeating pagers, they cannot build the automation needed to stop those alerts. True operational engineering means giving teams the time to build self-healing infrastructure that eliminates the need for manual midnight interventions.
Mistake 2 — Setting Unrealistic SLOs
In an effort to impress executives, engineering managers often set completely unrealistic Service Level Objectives, such as demanding absolute 100% uptime. This unrealistic goal creates a highly toxic engineering environment because achieving perfect availability is technically impossible in distributed systems.
It completely burns out your operations engineers and completely stalls feature releases, since any small change threatens the impossible metric. Wise technical leaders choose sensible reliability targets that align realistically with actual user expectations and business realities. This balanced approach protects team health while ensuring that product development continues moving forward at a healthy pace.
Mistake 3 — Ignoring Toil Until It’s Too Late
When engineering groups prioritize short-term feature delivery exclusively, they inevitably accumulate a massive amount of manual operational debt. Engineers gradually become buried under a mountain of repetitive manual tasks, like running manual patch scripts or fixing stuck server queues.
[Ignore Toil] -> [Manual Debt Accumulates] -> [Velocity Drops to Zero] -> [Burnout]
Eventually, this manual toil consumes their entire working day, leaving absolute zero time for strategic engineering work or automation design. Innovation grinds to a complete halt, system stability degrades, and your top engineering talent leaves the company due to frustration. Organizations must treat toil elimination as a non-negotiable weekly priority to keep their platforms running efficiently.
Mistake 4 — Skipping Blameless Postmortems
When an unexpected system outage occurs, human nature often drives people to look for someone to blame for the mistake. If leadership penalizes the engineer who pushed the wrong button, a highly toxic culture of fear quickly develops.
Engineers begin hiding system anomalies, avoiding risky architectural changes, and pointing fingers at other teams to protect themselves. Skipping truly blameless postmortems prevents your organization from learning from its inevitable operational failures. Teams must realize that human mistakes are symptoms of poorly designed systems, not the root cause of the breakdown.
Mistake 5 — Monitoring Without Actionable Alerts
Building massive, complex telemetry dashboards that display hundreds of flashing charts can easily create a false sense of security. If your paging system triggers an urgent alert for a non-critical issue that requires no immediate action, engineers develop severe alert fatigue.
They quickly learn to ignore notifications, which eventually causes them to miss an actual, catastrophic production outage alert. Every single alert configured in your system must point directly to a clear, actionable procedure that requires human intelligence to solve. If an issue can be resolved by a simple server restart, write a script to automate that restart instead of waking up an engineer.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software development teams often design complex application architectures in complete isolation without seeking input from operations specialists. They hand over the finished application code at the very last minute, expecting operations to run it smoothly in production.
This oversight regularly results in applications that are incredibly difficult to monitor, impossible to scale, and fragile under real-world traffic loads. Operations engineering expertise must be integrated right from day one of the software design phase. This collaboration ensures that telemetry hooks, configuration management, and scalability requirements are baked directly into the application code.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining deep visibility across complex distributed architectures requires a highly integrated suite of modern observability tools. Teams use Prometheus to collect granular, time-series metrics from containerized applications and cloud infrastructure components.
+-------------------------------------------------------------+
| OBSERVABILITY SUITE |
+------------------------------+------------------------------+
| Prometheus (Metrics) | Grafana (Visualization) |
+------------------------------+------------------------------+
| Datadog (Enterprise Tracing) | New Relic (Application Perf) |
+------------------------------+------------------------------+
They connect these data streams directly to Grafana dashboards to create highly scannable, real-time visual representations of system performance. For comprehensive enterprise environments, platforms like Datadog and New Relic provide deep application performance monitoring and automated tracing capabilities. These tools work together to ensure that engineering teams detect hidden systemic bottlenecks before they impact end users.
Incident Management
When a production system fails unexpectedly, response groups rely on specialized collaboration platforms to coordinate their mitigation efforts. PagerDuty acts as an intelligent routing engine that instantly alerts the specific engineers on duty based on live system telemetry.
These platforms integrate tightly with chat tools to spin up dedicated virtual incident rooms automatically. This automated coordination keeps communication organized, prevents duplicate troubleshooting efforts, and documents the timeline of the incident for later review. Utilizing structured incident management tools allows teams to dramatically reduce their overall mean time to resolution.
CI/CD & Release Engineering
Automating the software delivery process requires powerful continuous integration and continuous deployment engines that run validation tests seamlessly. Jenkins remains a widely utilized workhorse for orchestrating complex, customized build and packaging automation jobs across legacy environments.
In modern cloud-native architectures, GitOps controllers like Argo CD handle deployment synchronization automatically by matching live cluster states with code repositories. Spinnaker provides robust, multi-cloud deployment workflows that allow teams to execute safe canary rollouts and automated rollbacks with high confidence. These automation systems turn risky software deployments into completely predictable, hands-off engineering events.
Chaos Engineering
Building immense trust in system resilience requires specialized tools that inject controlled faults directly into live environments. Chaos Monkey operates as an automated testing agent that terminates random virtual machine instances inside production cloud environments.
This practice forces applications to maintain high availability by routing traffic away from failed nodes automatically without human intervention. By running continuous chaos experiments, teams discover hidden configuration mistakes, fragile network connections, and weak fallback logic safely. Embracing controlled failure injection transforms theoretical system reliability into proven operational resilience.
SLO Management
Tracking service level reliability against specific business thresholds requires dedicated platform tooling designed to analyze metrics over time windows. Nobl9 serves as a specialized platform that ingests raw telemetry data from multiple monitoring sources to calculate error budget consumption.
It provides clear, cross-functional dashboards that show both business stakeholders and engineers exactly how much error budget remains. These platforms trigger early warnings when a system consumes its operational safety margin too quickly. Having access to dedicated objective management tools helps teams make data-driven decisions regarding feature velocity and platform stability.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Entering the advanced world of cross-functional operations engineering requires a solid foundation in core technical competencies. Aspiring specialists must master the Linux command line, understanding file systems, process management, and advanced network configurations deeply.
[Linux Command Line & Networking] -> [Scripting: Python/Go] -> [Cloud & IaC]
They need to become highly proficient in scripting languages like Python or Go to automate repetitive administrative workflows. Additionally, understanding core networking protocols like TCP/IP, DNS, and HTTP/2 is absolutely non-negotiable for troubleshooting modern web platforms. Finally, specialists must master infrastructure-as-code principles using tools like Terraform to manage cloud infrastructure programmatically.
The Professional Learning Path
The professional educational journey begins with learning how to deploy and manage simple web applications on local virtual instances. Next, engineers should transition to learning containerization technologies by packaging applications into Docker containers.
From there, they progress to studying complex container orchestration platforms like Kubernetes to manage distributed systems at scale. Once comfortable with infrastructure management, engineers shift their focus toward mastering deep data observability and advanced telemetry design. The final stage involves learning how to design blameless incident response frameworks and alignment strategies for large enterprise organizations.
Certifications Worth Pursuing
Industry certifications provide a structured learning path and validate your technical expertise to potential employers across the global tech market. Pursuing foundational cloud architecture credentials from major public cloud vendors gives engineers a broad understanding of modern cloud services.
Earning specialized Kubernetes administration credentials proves your hands-on ability to configure and secure complex containerized clusters. Additionally, dedicated certifications in advanced observability platforms demonstrate your deep expertise in managing production telemetry systems. These industry credentials help engineers stand out in a competitive job market and accelerate their career growth.
Educational Resources with Xopsschool
Navigating this vast technical landscape can feel incredibly overwhelming without structured guidance and comprehensive professional mentorship. Aspiring engineers can find deeply technical, hands-on learning resources designed specifically for modern infrastructure challenges by studying with Xopsschool.
Their expert-led curriculum covers advanced topics including automated continuous deployment, deep infrastructure observability, and scalable system architecture. Students gain practical experience by working through real-world incident simulations and building automated self-healing software environments. Investing in structured education with a dedicated professional academy accelerates your journey toward mastering modern cross-functional operations engineering.
The Future of Systems Management
AI and Automation in System Optimization
The upcoming era of infrastructure management will be heavily shaped by the integration of machine intelligence into telemetry systems. Traditional alerting systems rely on fixed thresholds, which often trigger false alarms or completely miss complex, slow-burning anomalies.
Modern machine learning models analyze massive streams of live telemetry data to detect subtle performance deviations instantly. These intelligent systems can predict potential hardware failures and automatically optimize resource allocation before performance degrades. By speeding up root cause analysis, artificial intelligence allows human engineers to focus entirely on high-level architecture.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major structural evolution in how modern organizations deliver software infrastructure to internal teams. Instead of forcing every developer to learn complex cloud configurations, dedicated platform teams build unified self-service portals.
+-------------------------------------------------------------+
| INTERNAL DEVELOPER PLATFORM |
+-------------------------------------------------------------+
| [Click to Provision Database] [Click to Deploy Service] |
+-------------------------------------------------------------+
|
v (Automated Execution)
+-------------------------------------------------------------+
| Standardized Cloud Infrastructure |
+-------------------------------------------------------------+
These internal developer platforms provide pre-approved, highly secure, automated infrastructure templates that developers deploy with a single click. This approach dramatically reduces cognitive load on application developers while ensuring strict compliance with corporate security standards. Consequently, platform engineering accelerates organizational velocity while maintaining robust, standardized infrastructure across the entire company.
Management in Cloud-Native & Kubernetes Environments
As organizations continue migrating toward highly dynamic microservice architectures, managing containerized clusters presents unique orchestration challenges. Kubernetes has become the standard operating system for cloud-native applications, but its immense complexity requires deep specialization to manage effectively.
Future operations engineers must master advanced service mesh architectures to secure and observe service-to-service communication paths. They need to build highly automated scaling routines that respond dynamically to rapid shifts in global user traffic. Managing these highly fluid environments requires moving away from static server mindsets and embracing completely code-driven infrastructure orchestration.
Operational Skills That Will Matter Most
In the coming years, the most valuable infrastructure specialists will possess a unique blend of technical mastery and business acumen. Financial cost optimization engineering will become a critical priority as businesses seek to eliminate wasted cloud expenditure.
Engineers must learn to treat cloud spend as a core performance metric, optimizing code and resource allocation to maximize financial efficiency. Furthermore, deep data observability and cross-team communication skills will be highly sought after by enterprise employers. The future belongs to technical specialists who connect engineering performance directly to overall business success.
FAQ Section
- What is the standard career path for an operations specialist?Most professionals begin their careers as junior software developers or systems administrators before transitioning into specialized infrastructure engineering roles. With experience, they advance into senior infrastructure architect positions, designing global deployment frameworks and high-availability systems. Eventually, many move into strategic engineering leadership roles, directing cross-functional operational strategies and platform engineering groups across major technology enterprises.
- How does this discipline differ from traditional IT operations?Traditional IT operations relies heavily on manual administrative tasks, physical hardware management, and reactive troubleshooting workflows run by siloed teams. In contrast, modern operations engineering treats infrastructure entirely as software code, relying on automated pipelines and data-driven observability. This methodology shifts the focus from merely keeping servers running to proactively engineering scalable, self-healing software platforms.
- What are the typical salary trends for engineers in this field?Due to the immense complexity of managing modern distributed systems, qualified infrastructure and operations specialists command exceptionally high compensation worldwide. Entry-level engineers typically receive highly competitive salaries that surpass traditional IT support compensation packages by a significant margin. Senior architects and expert platform engineers often earn top-tier elite engineering salaries, accompanied by substantial stock options and bonuses.
- Which programming languages are most useful for infrastructure automation?Python remains a highly popular choice for writing versatile automation scripts, managing data pipelines, and interacting with cloud provider APIs efficiently. Go has emerged as an industry standard for cloud-native tool development because it compiles into fast, lightweight, independent binaries. Additionally, mastering bash scripting is essential for performing quick system adjustments and handling configuration management across Linux environments.
- How can small startups apply these principles without a large budget?Startups can implement core reliability principles efficiently by heavily leveraging managed cloud services that eliminate the need for complex internal management. They should focus on setting up basic, automated continuous deployment pipelines to keep their software deployment processes consistent. By establishing simple Service Level Objectives around critical user pathways, small teams maintain strong operational discipline without incurring massive financial overhead.
- What is alert fatigue and how do teams actively prevent it?Alert fatigue occurs when monitoring systems trigger too many non-critical notifications, causing engineers to become desensitized to urgent pages. Teams prevent this dangerous situation by ensuring that every single configured alert links directly to a documented, actionable procedure. Non-urgent anomalies should be routed to internal ticketing queues for review during normal business hours rather than waking up engineers.
Final Summary
Maintaining exceptional digital platform health requires a continuous, code-driven commitment to automation, systemic alignment, and deep behavioral observability. By breaking down ancient organizational silos and treating infrastructure entirely as software code, businesses achieve sustained engineering velocity without sacrificing platform stability. True operational excellence focuses on building highly resilient, self-healing systems that adapt to failures dynamically while consistently meeting customer expectations. As corporate platforms expand exponentially across global markets, adopting a unified cross-functional operations framework serves as the definitive cornerstone of modern enterprise success. Discover how your organization can master these advanced architectural strategies and build highly scalable, future-ready engineering teams by joining the professional programs at Xopsschool.