Imagine a massive retail platform crashing during a peak seasonal flash sale, bleeding millions of dollars per minute while developers and operations teams furiously point fingers at each other. This operational nightmare stems from traditional silos where software creation completely detaches from structural system maintenance.
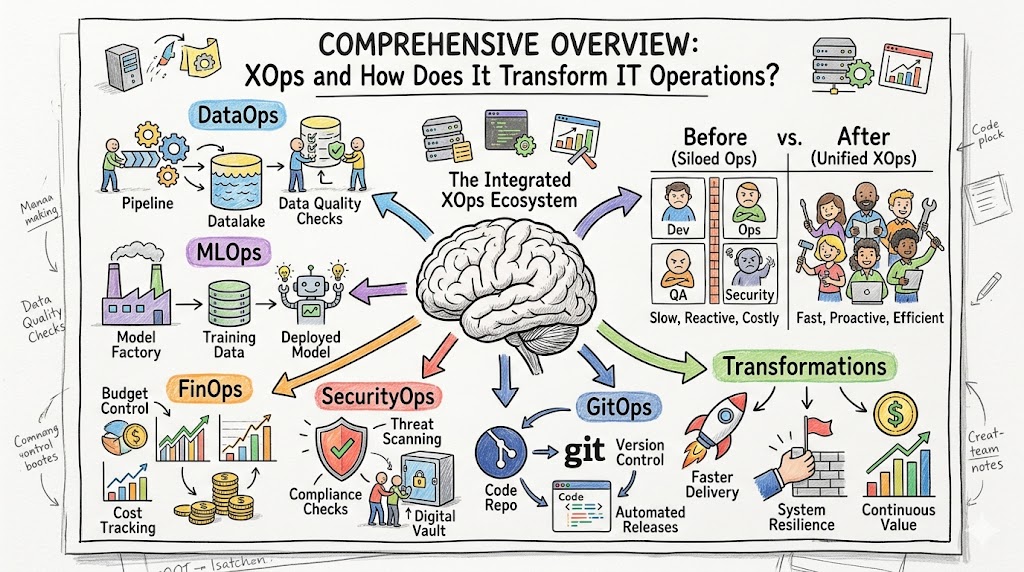
As digital environments expand exponentially, organizations require a unified methodology to handle scale, security, data, and machine learning pipelines simultaneously. This pressing demand introduces XOps, a comprehensive operational umbrella that integrates DevOps, DataOps, MLOps, FinOps, and GitOps into a singular, highly automated management philosophy.
This deep-dive technical guide uncovers the core architecture, foundational principles, practical metrics, and implementation frameworks necessary to build resilient IT ecosystems. Discover the ultimate paths toward organizational agility and system resilience through specialized masterclasses and immersive curriculum by visiting the premier instructional platform Xopsschool today to transform your production engineering capabilities.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Historically, system administration operated in a reactive vacuum where isolated teams manually configured physical servers. Developers threw raw application code over a metaphorical wall, leaving operations teams to figure out deployment nuances blindly. Consequently, minor configuration mismatches triggered massive systemic failures, long debugging cycles, and stagnant release schedules.
Moving Toward Unified Workflow Automation
As virtualization and cloud services emerged, the concept of infrastructure as code reshaped the entire corporate landscape. Organizations began treating server configurations with the same rigor as application code, which paved the way for automated testing pipelines. Breaking down these traditional departmental silos allowed software development and operational stability to merge into a single cohesive delivery pipeline.
Global Expansion Across Commercial Ecosystems
Modern enterprise environments have evolved far beyond basic application deployment into complex webs of microservices, multi-cloud clusters, and streaming data lakes. Therefore, these unified operational frameworks have expanded globally across large-scale tech enterprises, financial networks, and global logistics providers. Managing these highly distributed architectures requires continuous, automated governance across every single layer of the technological stack.
Defining Strategic Operations Management
The Core Operational Structure
The underlying architecture of advanced systems operations relies on continuous feedback loops, declarative infrastructure configurations, and centralized telemetry collection systems.
[Development Pipeline] ---> [Declarative Infrastructure] ---> [Production Deployment]
|
[Automated Remediation] <--- [Central Telemetry Systems] <--- [Continuous Monitoring]
Software defined policies govern every asset from code commits to live container orchestration platforms. Consequently, data flows predictably through automated validation gates, which ensures that production environments exactly mirror vetted architectural designs.
Daily Tasks of Systems Coordinators
Specialists in this domain dedicate their shifts to writing automated provisioning scripts, refining observability dashboards, and conducting architectural reviews. They systematically investigate performance anomalies, optimize CI/CD pipeline efficiency, and design self-healing mechanisms to handle transient network blips. Instead of manually fixing server issues, these engineers write software to manage infrastructure dynamically.
Localized Control vs. Broad System Architecture
Granular component tracking focuses exclusively on individual application metrics, microservices, or specific database queries. In contrast, broad system architecture addresses the holistic health, data dataflows, and dependencies of the entire multi-system infrastructure. Navigating between these two viewports allows engineers to resolve immediate bugs while preserving the long-term structural integrity of the global enterprise network.
The Efficiency Mindset
Transitioning to modern operations demands a profound cultural pivot from firefighting to proactive, intentional engineering. Teams prioritize systemic reliability, long-term stability, and continuous architectural improvement over short-term patch fixes. Ultimately, this specific mindset views every production incident as an educational opportunity to harden automation and remove human error completely.
The 7 Core Principles of XOps
1. Embracing Risk and Managing Variability
Perfection remains an impossible standard in highly complex, distributed software environments. Therefore, engineering teams acknowledge that components will eventually fail and instead design fault-tolerant systems capable of degrading gracefully. By managing acceptable systemic risk, companies maintain high operational velocity without jeopardizing foundational platform stability.
2. Establishing Service Level Objectives (SLOs)
Teams must define clear, measurable targets for systemic success to ensure that user expectations align with business priorities. These specific boundaries quantify acceptable performance levels regarding latency, availability, and throughput across all active services. Consequently, these metrics remove subjectivity from operational discussions and provide clear boundaries for development teams.
3. Eliminating Toil and Manual Processes
Repetitive, manual tasks that lack long-term strategic value act as a significant drag on engineering performance. Modern systems operations systematically target these administrative burdens, utilizing script automation and orchestration engines to eliminate them completely. Engineering away this operational debt frees up valuable human capital to build innovative, resilient infrastructure features.
4. Monitoring & Observability Across the Pipeline
Total visibility across the entire operational environment eliminates dangerous blind spots within distributed cloud topologies. This comprehensive approach combines structured logging, distributed tracing, and real-time metric aggregation to expose deep system states. Engineers quickly pinpoint the precise root causes of cross-component performance degradations before end-users experience any disruption.
5. Automation Over Manual Coordination
Relying on manual human communication to coordinate deployments or patch server vulnerabilities introduces significant delivery delays and errors. Smart software solutions, policy-driven engines, and declarative configurations handle these operations dynamically at scale. As a result, infrastructure scales seamlessly alongside fluctuating traffic volumes without requiring proportional increases in administrative headcount.
6. Release Engineering and Deployment Stability
Consistent, predictable, and secure software delivery relies on highly standardized release engineering strategies. Teams utilize canary deployments, blue-green environments, and automated rollback triggers to minimize blast radiuses during updates. These disciplined practices guarantee that application deployments proceed smoothly without threatening baseline system availability.
7. Simplicity in Network Architecture
Extremely complex environments directly increase failure surfaces and complicate incident remediation procedures. Embracing minimal, clean network architecture reduces hidden dependencies and makes system behavior much more predictable. Keeping configurations simple allows engineering teams to troubleshoot components faster and maintain high baseline security standards.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding operational health requires a precise breakdown of compliance, target, and measurement metrics.
- Service Level Agreement (SLA): A binding legal contract with end-users defining availability promises, carrying severe financial penalties if broken.
- Service Level Objective (SLO): An internal target metric that guides engineering teams to maintain operational stability before violating the SLA.
- Service Level Indicator (SLI): A specific, real-time measurement showing the actual performance of a compliance metric, such as request latency.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or performance degradation an application can legally afford within a set period. For instance, a 99.9% SLO allows a 0.1% error budget for innovation and feature deployment. If a team completely exhausts this budget due to unstable releases, all new features halt instantly to prioritize stability engineering.
Toil — The Silent Productivity Killer in Infrastructure
Toil encompasses administrative, manual tasks that are repetitive, automatable, tactical, and scale linearly with service growth. Left unchecked, it burns out talented engineers and stalls critical long-term platform development. Teams must continuously calculate hours spent on manual operations and use software engineering to systematically automate those workflows.
Incident Management & Postmortems
When unexpected production failures occur, structured incident management coordinates rapid restoration via designated roles and communications. Following resolution, teams conduct blameless postmortems to evaluate the structural root causes without pointing fingers at individuals. This open approach turns infrastructure bugs into systemic upgrades, ensuring the exact same failure never happens twice.
Capacity Planning
Predicting future resource requirements ensures that infrastructure handles seasonal traffic spikes smoothly without wasting money on idle hardware. Engineers analyze historical growth patterns, consumer usage trends, and system saturation indicators to forecast scaling needs accurately. This proactive planning prevents sudden resource exhaustion events during critical business quarters.
The Four Golden Signals of Pipeline Performance
To maintain complete infrastructure visibility, teams must constantly monitor four foundational metrics:
- Latency: The precise time it takes to service a specific request successfully.
- Traffic: A direct measure of total system demand, such as HTTP requests per second.
- Errors: The rate of requests that fail explicitly or implicitly across the environment.
- Saturation: A metric defining how full the most constrained system resource currently is.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
While culture focuses on shared organizational mindsets, breaking down silos, and embracing blameless failure, platform implementation deals with concrete technical realities. Culture encourages open collaboration across separate engineering departments, whereas implementation provides the software, APIs, and automated tools that turn those philosophical principles into functional daily realities.
Roles & Responsibilities Compared
The day-to-day duties within modern infrastructure management change significantly based on specific team alignments and core focus areas.
- Cultural Facilitators: Focus heavily on cross-departmental alignment, collaborative postmortems, and establishing shared organizational reliability goals.
- Platform Engineers: Design self-service developer portals, maintain centralized CI/CD templates, and build internal cloud hosting environments.
- Site Reliability Engineers: Code automated self-healing mechanisms, configure complex monitoring platforms, and directly manage production incident response.
- Data Operations Specialists: Optimize big data ingestion pipelines, govern storage schemas, and manage database scaling behaviors.
Can You Have Both Disciplines?
These separate engineering approaches naturally complement each other within progressive digital organizations. A healthy collaborative culture gives engineers the safety to design robust, standardized automated platforms. Conversely, having highly efficient self-service platforms eliminates friction, which reinforces a positive culture focused on speed and safety.
Which One Should Your Team Adopt?
Choosing an operational focus depends heavily on your current organization size, engineering maturity, and pressing infrastructure pain points.
| Organization Size | Primary Infrastructure Challenge | Recommended Focus Area |
| Early-stage Startup | Rapid feature validation, minimal budget, high velocity | Pure Cultural Alignment & Agile Automation |
| Mid-sized Enterprise | Growing infrastructure complexity, fragmented deployments | Centralized Platform Engineering Services |
| Massive Scale Organization | High transactional volume, complex compliance, global uptime | Dedicated Site Reliability Engineering Teams |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global software leaders utilize advanced real-time dashboards to correlate business KPIs directly with infrastructure performance indicators. For example, streaming platforms monitor packet delivery latency against user retention metrics to adjust edge-caching strategies instantly. This data-driven coordination ensures that engineering investments directly improve the digital customer experience.
Chaos Engineering Approaches to Resilient Systems
Prominent enterprises do not wait for unexpected outages to strike; they intentionally inject failures into production environments instead. By randomly disabling microservices or introducing artificial network delays, teams actively validate the resilience of their self-healing software architectures. This proactive experimentation exposes hidden architectural bugs long before they cause genuine customer disruptions.
Handling Reliability at Massive Scale
Distributed e-commerce applications routinely manage millions of simultaneous global checkouts by employing strict decoupling architectures. Systems process payments, update inventory, and dispatch shipping notifications across totally isolated asynchronous queues. Consequently, a sudden failure within the notification engine never stops a customer from successfully completing a purchase.
High-Availability in Fintech Operations
Financial transaction platforms operate under zero-tolerance mandates for downtime, data loss, and processing latencies. These entities rely on multi-region synchronous replication, hardware security modules, and instant automated failover mechanisms across diverse cloud networks. This rigid architecture guarantees total transaction accuracy even if an entire physical data center goes offline completely.
Scaled-Down but Essential Systems for Startups
Early-stage companies apply these core operational principles efficiently without incurring massive monetary or administrative overhead. By utilizing managed serverless compute engines and out-of-the-box observability suites, small teams automate their entire delivery pipelines. This strategic baseline allows them to scale rapidly without drowning in complex configuration management tasks.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many companies mistakenly view reliability engineering as a glorified, 24/7 manual technical support shifts rotation. True operations engineering focuses on writing proactive software to eliminate systemic vulnerabilities permanently rather than merely acknowledging endless pages. Treating engineers like firefighters causes extreme burnout and leaves fundamental infrastructure flaws unaddressed.
Mistake 2 — Setting Unrealistic SLOs
Demanding perfect 100% uptime represents an expensive, counterproductive operational goal that stifles organizational agility. Striving for zero downtime stalls feature releases completely, forces overly complex architectures, and drains critical engineering resources. Teams must set practical objectives that reflect actual user satisfaction thresholds to preserve innovation velocity.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring manual task accumulation builds up massive operational debt that eventually stalls entire development roadmaps. When engineers spend all their shifts running manual server patches or fixing broken data uploads, strategic scaling work stops entirely. Organizations must actively cap manual toil to keep engineering teams focused on high-value optimization tasks.
Mistake 4 — Skipping Blameless Postmortems
Punishing staff for operational errors creates an toxic corporate culture where engineers actively hide mistakes and clear systemic vulnerabilities remain unaddressed. Without transparent, blameless investigations, teams simply fix superficial bugs while leaving the underlying systemic issues to fail again. Open discussion transforms technical errors into critical structural improvements.
Mistake 5 — Monitoring Without Actionable Alerts
Configuring alerts for minor, non-critical metric fluctuations leads directly to dangerous engineering alert fatigue. When pagers sound constantly for events requiring no immediate intervention, engineers quickly learn to ignore notifications altogether. Every single alert must point directly to a clear system degradation and require immediate, manual human action to resolve.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Excluding infrastructure specialists from early application architecture discussions leads to fragile software designs that struggle in production environments. Developers frequently overlook critical scaling realities like connection pooling constraints, cache eviction policies, and distributed logging requirements. Integrating operational feedback from day one prevents costly retrofits later down the road.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete infrastructure visibility requires robust software suites capable of processing high-cardinality data at scale. Organizations deploy specific tools to gather precise real-time performance insights across their distributed networks.
| Tool Name | Core Specialization | Primary Operational Benefit |
| Prometheus | Time-series metric collection and alerting engine | Highly effective for monitoring dynamic container workloads |
| Grafana | Advanced data visualization and dashboard analytics | Centralizes disparate telemetry into unified command views |
| Datadog | Cloud-scale unified SaaS monitoring and analytics | Provides deep application performance tracing out of the box |
| New Relic | Full-stack observability and error tracking platform | Delivers end-to-end telemetry across legacy and cloud assets |
Incident Management
When critical outages strike, operations teams rely on dedicated platforms to coordinate internal responses and automate escalation pathways. PagerDuty organizes complex on-call rotations and routes critical system alerts to the correct on-call engineering squads instantly. This rapid orchestration reduces mean time to resolution and keeps stakeholder communication clear during major system disruptions.
CI/CD & Release Engineering
Automating the software delivery pipeline ensures that code changes pass through standardized quality and security checks smoothly. Teams utilize specialized execution platforms to test, package, and deploy applications predictably into production environments.
- Jenkins: A highly flexible, open-source automation engine used to build customized compilation and testing pipelines.
- Argo CD: A declarative, GitOps continuous delivery tool tailored specifically for deploying applications into Kubernetes clusters.
- Spinnaker: An enterprise-grade, multi-cloud continuous deployment platform designed for fast, repeatable canary releases.
Chaos Engineering
Uncovering hidden infrastructure flaws requires intentionally introducing controlled chaos directly into active environments. Chaos Monkey automatically terminates random virtual machine instances within production networks to test system resilience. This continuous, aggressive validation forces engineers to design robust, self-healing software architectures that withstand unexpected hardware dropouts.
SLO Management
Tracking service reliability against strict user thresholds requires centralized, dedicated compliance management software. Nobl9 integrates directly with existing monitoring tools to calculate error budgets and project service level trends clearly. This automation helps product owners and engineering leads make objective, data-backed choices regarding feature release velocities.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Entering this elite technical domain requires mastering deep Linux systems administration, bash scripting, and networking fundamentals. Aspiring engineers must gain proficiency in programming languages like Go or Python to build scalable automation tools comfortably. Additionally, a deep understanding of cloud infrastructure provisioning and container orchestration technologies remains non-negotiable for modern enterprise roles.
The Professional Learning Path
The educational journey begins with local application deployments, mastering basic version control systems, and configuring standard web servers manually. Next, engineers advance to infrastructure as code tools, continuous integration pipelines, and centralized logging setups. Senior progression focuses on distributed architecture design, complex disaster recovery planning, and driving systemic cultural transformations across entire organizations.
Certifications Worth Pursuing
Validating your technical infrastructure capabilities before major global employers requires obtaining industry-recognized professional credentials. Earning certifications from major cloud providers confirms your practical ability to design resilient, distributed architectures under pressure. Furthermore, specialized Kubernetes administration and site reliability credentials significantly boost your professional credibility and market valuation.
Educational Resources with Xopsschool
Navigating this vast, rapidly changing technological landscape requires structured, mentor-led guidance from proven industry veterans. Aspiring professionals accelerate their career growth by accessing the comprehensive deep-dive instructional programs curated by Xopsschool. Their immersive, hands-on labs provide the exact practical experience needed to master complex enterprise operations seamlessly.
The Future of Systems Management
AI and Automation in System Optimization
Artificial intelligence is rapidly reshaping modern operations by processing massive streams of telemetry data to identify anomalies proactively. Predictive algorithms spot subtle hardware degradation patterns and trigger automated self-healing scripts long before total failure occurs. This cognitive automation shifts incident management from rapid recovery to absolute, real-time prevention.
Platform Engineering — The Evolution of Infrastructure
The industry is moving quickly toward internal developer platforms that provide self-service infrastructure provisioning out of the box. Instead of filing manual configuration tickets, developers spin up compliant environments independently using standardized templates. This evolution removes organizational friction, improves security governance, and lets infrastructure experts focus on building core platform tools.
Management in Cloud-Native & Kubernetes Environments
As application footprints expand across massive, multi-region container clusters, managing dynamic networking states becomes highly complex. Service meshes and declarative configuration engines are becoming fundamental tools for controlling internal microservice communications safely. Succeeding in this landscape requires designing highly resilient policy gates that govern resource consumption automatically.
Operational Skills That Will Matter Most
The upcoming operational era will heavily prioritize granular cloud financial management alongside deep data lineage observability. Engineers must look beyond basic uptime metrics to focus on optimizing infrastructure spend and securing complex data flows. Blending deep technical expertise with strategic financial awareness will define the next generation of infrastructure leaders.
FAQ Section
- What are the foundational prerequisites for entering this specific technical career path?Aspiring specialists need a strong grasp of Linux operating system internals, basic networking protocols, and code version control systems. Proficiency in a modern scripting language like Python or Go is highly critical for building infrastructure automation tools.
- How does this operational methodology differ fundamentally from traditional DevOps practices?DevOps focuses primarily on breaking down organizational silos to unite software development and system deployment pipelines smoothly. This modern framework extends that philosophy by using specific software engineering metrics to guarantee long-term production reliability.
- What are the standard market salary trends for certified infrastructure automation specialists?Experienced professionals in this field command excellent compensation packages globally due to the critical nature of their work. Senior architects and reliability engineers frequently receive premium offers that outpace general software development roles significantly.
- Why is an error budget considered so critical for modern product development cycles?An error budget provides a clear, mathematical framework that balances fast feature innovation with essential platform stability. It removes emotional arguments between departments, defining exactly when a team must pause deployments to fix core infrastructure.
- Which specific automation tools should a beginner focus on learning first?Beginners should prioritize mastering Docker for containerization, Git for configuration tracking, and basic cloud platform mechanics. Next, transition toward learning infrastructure provisioning engines like Terraform and container orchestration suites like Kubernetes.
- How do enterprise organizations measure the business value of these operational practices?Companies evaluate success by tracking declines in mean time to resolution and significant drops in total production service outages. Ultimately, these disciplined engineering practices protect corporate revenue, accelerate feature release speeds, and boost end-user customer satisfaction.
Final Summary
Sustaining high digital operational performance requires a profound transition from traditional reactive server administration to proactive software-driven infrastructure management. By embracing objective measurement systems, automated processes, and blameless engineering cultures, companies ensure long-term stability at massive scale. Organizations that prioritize these modern workflows successfully insulate their systems from catastrophic failures while maintaining rapid development velocity. Take your team’s technical capabilities and pipeline resilience to the ultimate level by partnering with Xopsschool to master these critical modern engineering frameworks today.