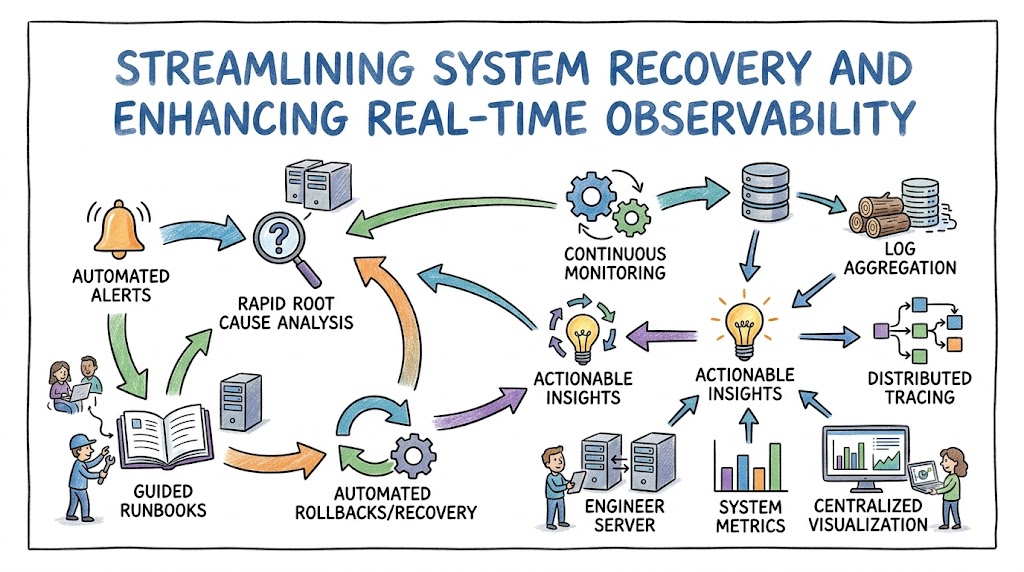
DevOps fundamentally reshapes how modern software organizations identify and mitigate production anomalies. Historically, traditional development and operations teams worked in rigid isolation, which unfortunately delayed critical communication during major system outages. By breaking down these organizational barriers, engineering teams can now implement automated monitoring workflows that immediately flag architectural failures. Consequently, this collaborative approach minimizes the average time required to acknowledge and resolve active system incidents. Discovering efficient incident response strategies becomes straightforward when professionals utilize comprehensive educational ecosystems like Xopsschool to master foundational infrastructure concepts.
Furthermore, the continuous integration and continuous deployment pipeline provides deep visibility into recent code modifications. Because automated testing frameworks validate software continuously, engineers can quickly correlate sudden performance drops with specific deployment payloads. This proactive stance ensures that operations engineers do not waste valuable time manually combing through massive application logs. Ultimately, the integration of shared responsibilities ensures that software deployment remains highly resilient, consistently reliable, and remarkably stable under heavy user traffic.
Key Operational Concepts You Must Know
Understanding Observability and Monitoring Essentials
Engineering teams must distinguish between traditional monitoring methodologies and modern observability frameworks to maintain high system availability. Monitoring explicitly tracks known failure signatures by collecting pre-defined system metrics like processor utilization or memory consumption. Conversely, observability empowers system administrators to infer the internal states of a complex system based on external outputs. This comprehensive practice relies heavily on collecting metrics, centralized logs, and distributed requests traces systematically.
Consequently, having full visibility allows engineers to debug highly unpredictable architectural behaviors that standard alerts miss entirely. By utilizing structured data streams, developers can proactively pinpoint exactly where a specific query causes unexpected network latency. Therefore, integrating deep observability across your entire infrastructure remains an absolute prerequisite for maintaining optimal service delivery and application performance.
Establishing Service Level Objectives and Error Budgets
Managing production systems effectively requires quantifiable performance metrics that establish realistic reliability goals for development teams. A Service Level Indicator measures a specific aspect of compliance, whereas a Service Level Objective defines the target reliability level. For instance, an organization might dictate that their primary authentication API must remain fully functional for exactly 99.9% of requests. This targeted objective directly creates an error budget, which represents the total allowable downtime over a specific duration.
Therefore, if the engineering team consumes the entire error budget due to frequent incidents, they must immediately halt feature development. This practical threshold beautifully balances the rapid delivery of innovative features with the absolute stability of the underlying infrastructure. As a result, product managers and operations engineers can collaborate objectively without experiencing conflicting priorities regarding release schedules.
| Operational Metric | Primary Technical Focus | Practical Business Outcome |
| Service Level Indicator (SLI) | Tracks real-time performance variables | Provides precise operational data |
| Service Level Objective (SLO) | Defines the targeted reliability threshold | Aligns engineering goals with user needs |
| Error Budget | Measures allowable system downtime | Balanges feature velocity with stability |
Automating Alerting and On-Call Rotations
Manual intervention during complex system outages frequently introduces human errors and significantly prolongs overall resolution times. Because of this risk, modern enterprise organizations leverage automated alerting systems that route contextual notifications to specific engineering teams. These intelligent frameworks filter out harmless background noise and only escalate critical anomalies that require immediate technical attention. Consequently, on-call engineers receive actionable alerts containing direct links to relevant diagnostic dashboards and specific runbooks.
Furthermore, structuring equitable on-call schedules prevents employee burnout and ensures that someone always stands ready to mitigate production issues. By rotating operational duties among all engineering team members, everyone gains a deep, practical understanding of system vulnerabilities. This shared operational responsibility ultimately fosters a healthier engineering culture focused on long-term systemic improvement and automated remediation.
Platform Implementation vs. Culture — What’s the Real Difference?
The Mechanics of Engineering a Robust Platform
Building an internal developer platform requires specialized technical design, robust infrastructure automation, and the integration of diverse software tools. Engineering teams focus heavily on provisioning cloud resources dynamically, configuring secure networks, and managing container orchestration systems. For example, they build automated pipelines using infrastructure as code to guarantee that testing and production environments remain completely identical. These concrete systems provide developers with self-service capabilities that remove traditional operational dependencies entirely.
However, simply deploying sophisticated deployment tools does not guarantee that your software delivery lifecycle will automatically improve. Without proper integration, developers might circumvent the platform entirely, which quickly leads to fragmented workflows and shadow IT infrastructure. Therefore, platform implementation must be viewed as a technical catalyst that requires continuous maintenance, refinement, and user-centric optimization.
+-----------------------------------------------------------------------+
| PLATFORM IMPLEMENTATION |
| [Infra as Code] ---> [CI/CD Pipelines] ---> [Container Clusters] |
+-----------------------------------------------------------------------+
|
REQUIRES ALIGNMENT WITH
v
+-----------------------------------------------------------------------+
| DEVOPSSCHOOL CULTURE |
| [Shared Responsibility] -> [Blameless Postmortems] -> [Automation] |
+-----------------------------------------------------------------------+
Cultivating an Automated and Collaborative Mindset
An elite operational culture centers around shared accountability, continuous learning, and the complete elimination of historical departmental silos. Teams prioritizing cultural alignment view production failures as valuable opportunities to analyze systemic architectural weaknesses rather than punish individual engineers. For this reason, they actively practice blameless post-mortems to discover the root cause of an incident without assigning personal fault. This psychological safety encourages developers to communicate transparently about system defects early in the software development cycle.
Additionally, a healthy operational mindset encourages engineering teams to prioritize sustainable automation over repetitive manual labor. When engineers actively share a collective passion for optimizing system reliability, they naturally write cleaner, more maintainable software code. Ultimately, culture provides the essential philosophical foundation that transforms raw technical tools into a highly efficient, cohesive delivery mechanism.
Balancing Technology and Human Workflows
Achieving true operational excellence requires organizations to balance technical platform capabilities carefully with human organizational workflows. If a company focuses exclusively on adopting new technologies, engineers become overwhelmed by tool sprawl and complex operational procedures. Conversely, focusing solely on cultural principles without providing modern automated tooling leads to extreme developer frustration and slow execution. Therefore, successful enterprises intentionally design their technical platforms to reinforce their desired cultural behaviors seamlessly.
| Operational Dimension | Platform Implementation Focus | Cultural Mindset Focus |
| Primary Objective | Building automated self-service infrastructure | Fostering collaboration and shared responsibility |
| Core Tooling | CI/CD pipelines, cloud resources, containers | Blameless post-mortems, knowledge sharing |
| Success Metric | Deployment frequency and infrastructure uptime | Team cohesion, psychological safety, innovation |
Real-World Use Cases of Modern Operations
Mitigating E-Commerce Outages During Peak Traffic
During major global shopping events, large e-commerce platforms experience massive surges in concurrent user traffic that stress database clusters. In a traditional setting, a sudden memory leak on the checkout microservice could remain undetected until frustrated customers complain. However, modern operational practices leverage real-time anomaly detection algorithms that instantly flag unusual latency spikes in the checkout pipeline. This automated trigger immediately scales up container instances to distribute the traffic load before the application crashes completely.
Concurrently, automated alerts notify the designated on-call response team while attaching precise log snippets from the affected containers. Because the platform automatically isolates the failing microservice instance, engineers can safely inspect system telemetry without disrupting active shoppers. Consequently, the enterprise maintains its revenue streams while demonstrating how automated observability mitigates severe financial risks effectively.
Resolving Microservice Failures in Financial Applications
Financial technology platforms process millions of secure transactions daily across highly complex, distributed microservice architectures. If a legacy payment gateway experiences intermittent network timeouts, locating the exact point of failure manually feels nearly impossible. By utilizing distributed tracing, operations engineers can visually follow the exact path of a single transaction across dozens of independent services. This detailed architectural visibility allows developers to see that a specific database lock is causing downstream payment delays.
[User Request]
|
v
[Gateway Service] ---> (Latency Detected Here)
|
+---> [Auth Service] (Healthy)
|
+---> [Payment Service] ---> [Database Lock Event] (Root Cause Located!)
Once identified, the team can quickly implement a temporary circuit breaker pattern to safely route transactions through an alternative gateway. Because the operational framework provides instant diagnostic feedback, the engineering team resolves the issue in minutes rather than hours. Therefore, comprehensive telemetry protects transactional integrity and reinforces consumer trust in critical digital banking services.
Handling Automated Rollbacks for Cloud Deployments
A fast-growing software company frequently deploys new feature updates directly to production environments throughout the business day. During a routine afternoon release, an unnoticed software bug accidentally causes global system resource consumption to spike dramatically. Fortunately, the automated deployment pipeline continuously monitors post-deployment error rates against established baseline metrics. Because the system detects a sharp increase in HTTP 500 error responses, it halts the rollout process automatically.
Furthermore, the deployment platform instantly initiates an automated rollback to the last known stable configuration version. This entire remediation process occurs within seconds without requiring any manual intervention from the engineering team. As a consequence, end users experience absolutely zero service interruption, while developers receive a clean environment to debug their code safely.
Common Mistakes in Operations Engineering
Over-Engineering Alert Systems and Dashboard Fatigue
A frequent trap for growing engineering departments is creating overly complex alerting systems that notify teams for every minor fluctuation. When engineers receive dozens of non-critical pages throughout the night, they quickly develop severe alert fatigue. Consequently, they begin to ignore notifications or mute communication channels, which eventually causes them to miss genuine production outages. Dashboards cluttered with hundreds of unorganized, irrelevant charts further compound this issue by obscuring critical infrastructure data.
To resolve this dilemma, teams must ruthlessly audit their alerting frameworks and only page humans for actionable, customer-impacting events. Non-urgent systemic anomalies should be routed to internal ticketing queues or automated remediation scripts for asynchronous resolution. Maintaining clean, highly focused operational dashboards ensures that response teams can quickly diagnose architectural issues during high-stress incidents.
Ignoring Technical Debt in Infrastructure Code
Treating infrastructure as code with less discipline than application code introduces significant hidden technical debt into production environments. Many teams rapidly copy unverified configuration templates or skip writing comprehensive validation tests for their deployment automation scripts. Over time, this negligence leads to highly fragile deployment environments, configuration drift, and undocumented architectural dependencies. When a critical infrastructure component inevitably fails, troubleshooting the root cause becomes an incredibly difficult and error-prone process.
Fragile Templates ---> Missing Automated Tests ---> Configuration Drift ---> System Failure
Therefore, engineering organizations must apply strict software development best practices to all infrastructure code repositories. This essential discipline includes conducting rigorous peer code reviews, running automated static analysis tools, and maintaining comprehensive documentation. By keeping your infrastructure code pristine, you guarantee that your environment provisioning remains completely predictable, highly secure, and easily reproducible.
Neglecting Post-Incident Learning and Documentation
Resolving a critical production outage without conducting a thorough retrospective analysis guarantees that the exact same issue will recur. Far too many organizations simply patch a symptom, close the active incident ticket, and immediately return to feature development. This hurried approach leaves the underlying root cause completely unaddressed while failing to update outdated system runbooks. Consequently, engineering teams repeat past mistakes, which continually degrades long-term system reliability and drives up operational costs.
[Incident Occurs] ---> [Quick Fix Applied] ---> [No Retrospective] ---> [Same Incident Recurs]
Preventing this cycle requires teams to dedicate adequate time to writing comprehensive, collaborative post-mortem documents after every major incident. These documents must clearly detail the timeline of events, the specific root causes, and clear action items for prevention. Sharing this knowledge openly across the entire organization fosters systemic resilience and empowers other teams to safeguard their services.
How to Become an Operations Expert — Career Roadmap
Mastering Core Skills for Aspiring Engineers
Embarking on a career in operations engineering requires a solid foundation in Linux systems administration, networking protocols, and basic programming languages. Aspiring professionals must feel comfortable navigating the command line interface, managing file systems, and configuring network routing tables. Additionally, learning a scripting language like Python or Bash allows engineers to automate repetitive administrative tasks efficiently. Understanding how internet systems communicate via HTTP, TCP/IP, and DNS is also vital for troubleshooting distributed web applications.
Furthermore, developing strong communication and problem-solving skills is just as critical as mastering technical operational tools. Operations experts must translate complex technical anomalies into clear business impacts when communicating with non-technical organizational stakeholders. Cultivating a curious, analytical mindset ensures you can logically isolate system failures under pressure during high-stakes outages.
Advanced Specializations within Operations
Once you master foundational operational skills, you can specialize in high-demand domains like Site Reliability Engineering or Platform Engineering. Site Reliability Engineering focuses heavily on applying software engineering principles directly to infrastructure scalability and reliability challenges. Platform Engineering centers on building secure, efficient internal developer platforms that optimize the software delivery experience for internal teams. Both specialized career paths require deep expertise in container orchestration systems like Kubernetes and cloud computing architectures.
- Site Reliability Engineer (SRE): Focuses on system availability, automation, creating robust monitoring solutions, and managing error budgets.
- Platform Engineer: Focuses on developer self-service tools, optimizing internal CI/CD pipelines, and maintaining infrastructure blueprints.
- DevSecOps Specialist: Focuses on integrating automated security scanning tools directly into the continuous software deployment pipeline.
- Cloud Architect: Focuses on designing highly resilient, cost-effective, and scalable multi-cloud infrastructure environments for enterprise applications.
Recommended Learning Pathways and Communities
Achieving true mastery in operations engineering requires a dedication to continuous learning and active participation in professional technical communities. Engaging with open-source infrastructure projects provides invaluable practical experience with cutting-edge tools and real-world system architectural designs. Furthermore, attending specialized industry conferences, reading technical blogs, and participating in local meetups keeps your knowledge current. Utilizing comprehensive, mentor-led educational platforms allows you to systematically build hands-on skills through realistic, sandbox-based architectural labs.
| Phase | Recommended Learning Focus | Suggested Action Item |
| Beginner | Linux internals, Bash scripting, foundational networking | Set up a personal home lab server |
| Intermediate | Git workflows, CI/CD pipelines, Docker containers | Automate an application deployment |
| Advanced | Kubernetes orchestration, Infrastructure as Code, Observability | Architect a multi-region cloud layout |
FAQ Section
- How does DevOps directly accelerate the incident detection process?
DevOps accelerates detection by integrating real-time automated monitoring tools and distributed tracing directly into the deployment pipeline. These systems immediately identify anomalous performance variations and notify the on-call response team long before users notice any degradation.
- What role does automation play in modern infrastructure incident response?
Automation eliminates slow manual diagnostic steps by instantly triggering self-healing scripts, auto-scaling cloud resources, or executing rollbacks. This swift automated intervention drastically minimizes system downtime and frees up human engineers to focus on root-cause analysis.
- Why are blameless post-mortems critical for long-term system reliability?
Blameless post-mortems focus on identifying systemic architectural or procedural weaknesses rather than punishing individual human errors. This supportive environment encourages engineering teams to share incident data transparently, which directly leads to robust preventative measures.
- What is the difference between monitoring and observability in cloud environments?
Monitoring tracks predefined metrics to notify teams when systems pass known failure thresholds, focusing on known issues. Observability leverages logs, metrics, and deep traces to allow engineers to understand entirely new, unpredictable system behavior.
- How can small engineering teams start implementing DevOps operational practices?
Small teams can begin by automating their deployment pipelines, tracking basic application metrics, and establishing centralized logging systems. Prioritizing clear communication and defining simple on-call rotations lays a strong foundation for scaling operational efficiency later.
Final Summary
Embracing modern operational methodologies completely transforms how engineering organizations manage service reliability and handle unexpected production incidents. By integrating automated observability frameworks with a healthy collaborative culture, teams drastically reduce their overall time to detect and resolve system anomalies. This proactive operational posture not only protects corporate revenue streams but also significantly enhances the end-user customer experience. Moving away from legacy siloed workflows allows developers and administrators to share deep architectural insights, continuously optimizing system performance.
Ultimately, building resilient infrastructure requires a continuous investment in both advanced platform technologies and human engineering skill sets. As cloud architectures evolve, staying proficient in automated deployments, configuration management, and distributed tracing remains essential for career growth. Organizations that cultivate an elite operational mindset successfully empower their engineers to innovate rapidly while maintaining exceptional application stability. Embracing these core methodologies ensures your delivery ecosystem remains fully optimized to navigate the complex challenges of modern enterprise computing.