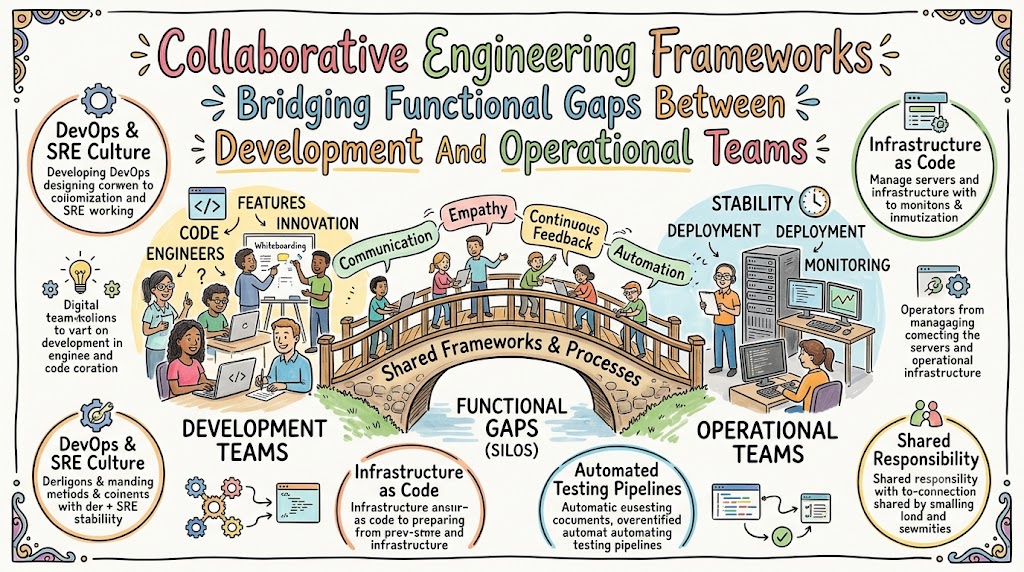
Imagine a catastrophic database deadlock striking your primary payment gateway at midnight during a high-traffic flash sale. The software developers immediately claim that the code functions perfectly in their local environments, whereas the infrastructure engineers point out that memory utilization spiked inexplicably. Consequently, this finger-pointing dynamic prolongs the production outage, drains company revenue, and fractures internal team morale. This classic operational bottleneck highlights why traditional methods fail under sudden structural strain.
Modern enterprise software systems demand a unifying paradigm that combines software intelligence with infrastructure management. Cross-functional operational frameworks, frequently categorized under the overarching umbrella of XOps, resolve these systemic friction points by embedding development principles directly into operations. Transitioning to this integrated model ensures that engineering teams can scale systems rapidly without sacrificing platform uptime. Therefore, companies can replace standard manual interventions with predictable, automated delivery pipelines.
This comprehensive guide serves as an architectural deep dive into the strategic principles, core metrics, and operational workflows that unite software development and infrastructure management. We will explore the vital mechanics of error budgets, actionable observability, and resilient cultural structures. Furthermore, you will discover the foundational technologies that top-tier enterprises use to maintain continuous deployment stability.
To master these cross-functional workflows and accelerate your deployment speeds safely, you should explore the specialized curriculum offered at Xopsschool. This platform delivers structured technical deep dives designed to help you transform fragmented legacy pipelines into highly resilient, automated environments. Let us begin by analyzing how modern systems infrastructure reached this critical inflection point.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
For many years, corporate software environments functioned within isolated departments that rarely communicated directly. Developers focused entirely on writing code and pushing out features as quickly as possible. Meanwhile, separate operations teams received this completed code and inherited the sole responsibility for maintaining its runtime stability.
Consequently, this structural division created severe operational friction because developers faced rewards for making constant changes, while operations specialists strove to minimize system changes to protect uptime. When new updates triggered production failures, resolving the underlying issue became a lengthy, contentious process. Manual server configurations, untracked environmental differences, and undocumented patches further worsened these early operational bottlenecks.
Moving Toward Unified Workflow Automation
As cloud infrastructure emerged, organizations realized that manual system configurations could no longer keep pace with rapid software delivery demands. Therefore, pioneers in the industry began treating system infrastructure as if it were regular software code.
[Development Teams] ---> (Shared Automated Workflows) <--- [Operations Teams]
|
v
[Unified Production Release]
By adopting version control systems for infrastructure definitions, teams successfully unified their operational workflows and wiped out human errors. This major transition eliminated the traditional “throw it over the wall” mindset that defined earlier decades. Automated testing, continuous integration, and standardized environments soon transformed code deployment from a risky monthly event into a predictable daily routine.
Global Expansion Across Commercial Ecosystems
Subsequently, these unified automation concepts quickly expanded beyond internet-scale pioneers into major global commercial markets. Enterprise sectors like healthcare, logistics, and retail recognized that software delivery speed directly impacted their marketplace survival.
As a result, organizations adopted standardized cross-functional practices to remain highly competitive. This global expansion forced legacy IT frameworks to evolve into nimble, programmable systems capable of managing thousands of microservices simultaneously. Today, integrated automation frameworks represent the definitive baseline standard for any business aiming to scale its digital services efficiently.
Defining Strategic Operations Management
The Core Operational Structure
At its fundamental level, strategic operations management treats infrastructure stability as an ongoing software engineering problem. The core structure relies on creating tight feedback loops between application runtime environments and development workspaces.
Instead of treating servers as uniquely configured entities, teams define everything through programmatic, version-controlled manifests. System metrics, application logs, and network trace data constantly flow back into telemetry systems to provide an updated snapshot of holistic system health. This continuous data loop allows engineering squads to detect microscopic anomalies before they turn into full-scale production outages.
Daily Tasks of Systems Coordinators
Systems coordinators and site reliability specialists perform a wide variety of advanced technical tasks to ensure long-term platform resilience. They focus heavily on coding automated self-healing scripts that automatically restart failing microservices or reallocate clustered cloud storage.
Additionally, these engineers build robust deployment pipelines, review architectural changes for potential failure modes, and tune alerting thresholds to prevent notification fatigue. They also conduct detailed capacity simulations to ensure that corporate networks can withstand sudden traffic spikes. Instead of putting out fires manually, they spend their days building the automated systems that prevent those fires from starting.
Localized Control vs. Broad System Architecture
Managing modern systems requires balancing small-scale component tracking against large-scale global architecture. Localized control focusing on individual container metrics or single-instance database queries is certainly important.
However, true operational excellence requires a wider architectural perspective that tracks how interconnected services behave across multiple cloud regions. Systems coordinators must understand the cascading impacts that occur when a single microservice experiences minor network latency. Therefore, they focus their engineering efforts on systemic patterns, load-balancing mechanisms, and overarching data consistency models rather than obsessing over isolated servers.
The Efficiency Mindset
Transitioning to an integrated operational model demands a profound shift in organizational culture and human mindset. Teams must actively abandon the outdated notion that system perfection is achievable through rigid restriction.
Instead, the efficiency mindset acknowledges that production failures are inevitable characteristics of complex distributed software systems. Engineers proactively design systems to tolerate component failures gracefully rather than trying to prevent every single error. This strategic perspective prioritizes scalable automation, continuous architectural experimentation, and long-term system predictability over short-term manual fixes.
The 7 Core Principles of XOps
1. Embracing Risk and Managing Variability
The first fundamental principle establishes that trying to run a complex software system with absolutely zero downtime is counterproductive. Attempting to achieve 100% uptime costs an exorbitant amount of money and halts all feature innovation.
Instead, engineering teams focus on defining and managing acceptable levels of systemic risk. They identify exactly how much variation their user base can tolerate before the overall customer experience drops. By accepting risk as a natural variable, organizations can safely accelerate feature releases while keeping their main services highly stable.
2. Establishing Service Level Objectives (SLOs)
To manage system risk effectively, engineering groups must construct clear, quantifiable Service Level Objectives (SLOs). These internal metrics act as the primary compass guiding development and infrastructure operations.
Teams establish these targets based on what matters most to the end user, such as response speed or API success rates. Setting these objective standards eliminates emotional debates between product managers and engineering squads regarding deployment safety. If an infrastructure metric remains safely within its designated objective boundaries, the development team can continue releasing new updates without delay.
3. Eliminating Toil and Manual Processes
Toil refers to repetitive, manual, operational work that lacks long-term strategic value and can be scaled away through automation. Examples include manually resetting application servers, creating user accounts one by one, or manually copying log files.
Modern operations frameworks place a strict limit on how much time engineers can spend on these repetitive administrative chores. Teams actively dedicate a significant portion of their engineering hours to writing software that permanently automates these manual processes. Eliminating this operational drag ensures that engineers remain focused on high-value projects that improve overall system resiliency.
4. Monitoring & Observability Across the Pipeline
Comprehensive visibility across the entire software delivery pipeline prevents catastrophic blind spots from hiding in production. Observability goes far beyond simply knowing whether a cloud server is turned on or off.
It requires gathering detailed telemetry data that maps how individual requests travel through a complex web of microservices. Engineers implement distributed tracing, structured application logging, and granular metric collection across every single layer of their tech stack. This comprehensive visibility allows teams to pinpoint the exact root cause of an obscure performance bottleneck within seconds.
[System Request] ---> [API Gateway Log] ---> [Microservice Trace] ---> [Database Metric]
5. Automation Over Manual Coordination
When scaling complex environments, relying on human coordination to update servers or change network rules introduces major risks. Therefore, modern systems engineering prioritizes programmatic automation over human intervention at every opportunity.
Whether provisioned through declarative cloud templates or automated script engines, changes happen systematically through software. If a system requires modifications, engineers update the central code repositories rather than logging directly into production servers. This approach ensures that every deployment remains completely auditable, repeatable, and independent of manual guesswork.
6. Release Engineering and Deployment Stability
Release engineering is a dedicated discipline focused on building, testing, and deploying software packages in a reliable, consistent manner. Operational excellence depends on making these release mechanisms as boring and predictable as possible.
Engineers implement advanced deployment techniques like canary releases and blue-green environments to minimize the blast radius of new updates. By routing a tiny fraction of live user traffic to a new version first, teams can verify its stability safely. If the system detects any anomalies, automated rollback mechanisms instantly restore the previous version to prevent widespread customer impact.
7. Simplicity in Network Architecture
Complex software environments are inherently difficult to secure, maintain, and troubleshoot effectively. Therefore, maintaining strict simplicity within your network and system architecture directly reduces potential failure surfaces.
Engineers achieve this by removing dead components, standardizing data access paths, and avoiding over-engineered software configurations. Clean, simple systems are far easier to model, observe, and repair when unexpected bugs emerge. By intentionally rejecting unnecessary technical complexity, teams build a highly resilient framework that scales naturally with demand.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the subtle distinctions between these three metrics is critical for managing modern system expectations. While they sound highly similar, they serve entirely different audiences and operational purposes.
- Service Level Indicator (SLI): This represents a precise, compliance-based measurement of a system’s current performance at a specific point in time. For example, it tracks whether your home webpage loads in under 200 milliseconds.
- Service Level Objective (SLO): This is a target reliability percentage defined for an SLI over an extended period. For instance, your team might agree that the home webpage must load in under 200 milliseconds for 99.5% of requests over a rolling 30-day window.
- Service Level Agreement (SLA): This is the legal, business-level contract made directly with external clients or consumers. It explicitly states the financial penalties, refunds, or service credits your company must provide if you fail to meet the agreed SLO.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or system performance degradation your application can safely tolerate before impacting customers. Mathematically, it is the simple inverse of your established Service Level Objective ($100\% – \text{SLO}$). If your engineering team sets a rolling monthly SLO of 99.9% availability, your remaining error budget is exactly 0.1%.
Total Service Budget (100%)
|---------------------------------------------------------|---------|
Uptime Target (99.9% SLO) Error Budget (0.1%)
This structural concept creates a beautiful self-balancing mechanism for software delivery teams. As long as your system retains a healthy chunk of its monthly error budget, developers can release experimental features rapidly. However, if a series of buggy deployments consumes the remaining error budget, the team must immediately pause all new features. They must then redirect 100% of their engineering capacity toward fixing infrastructure reliability, bugs, and automated testing pipelines.
Toil — The Silent Productivity Killer in Infrastructure
Toil is any operational work that tends to be manual, repetitive, automatable, tactical, and devoid of enduring value. It scales linearly with your user base; if managing twice as many users requires doubling your team’s support hours, you are dealing with toil. Left unmanaged, toil completely drains engineering velocity and burns out your most talented specialists.
To eliminate this productivity killer, teams must track their time meticulously and identify repetitive manual workflows. If an engineer spends four hours every Monday manually clearing disk space on temporary staging servers, that task must be flagged for automation. By writing a script that automatically purges old cache directories when disk usage hits 80%, the team completely engineers that toil away.
Incident Management & Postmortems
When a critical system component breaks, a well-defined incident management process prevents chaotic triage efforts. The primary objective during an outage is restoring normal service operations as quickly as possible, not finding out who caused it. Teams use dedicated communication channels, clear internal command hierarchies, and automated alerting systems to coordinate their response.
Once the incident concludes and services return to normal, the team conducts a comprehensive blameless postmortem. This practice assumes that every engineer acted with good intentions based on the information they had at the time. Instead of pointing fingers at human error, the team uncovers the structural gaps in the code or architecture that allowed the human error to occur.
Capacity Planning
Capacity planning is the proactive process of forecasting future infrastructure needs to prevent system failures before they happen. Teams must look ahead to ensure they have enough computing power, storage space, and network bandwidth to handle growth. This requires analyzing past utilization trends alongside upcoming business goals, such as a major marketing push or global expansion.
By conducting regular capacity simulations and load testing sessions, engineers identify exactly where their systems will buckle under intense pressure. For instance, a simulation might reveal that while cloud servers scale smoothly, your core relational database runs out of available connection pools at 50,000 concurrent users. Discovering these architectural scale limits early allows your team to upgrade components calmly before live production traffic strikes.
The Four Golden Signals of Pipeline Performance
If you can only monitor a handful of high-level metrics across your software infrastructure, you should focus entirely on the four golden signals. These critical performance metrics provide a holistic view of system health and immediately flag anomalies.
| Metric Signal | Operational Focus and Target Evaluation |
| Latency | The precise time it takes to service a request successfully, distinguishing between successful and failed queries. |
| Traffic | A measure of how much demand is being placed on the system, tracking total HTTP requests per second or network bandwidth. |
| Errors | The rate of requests that fail completely, tracking explicit 500-level status codes or implicit data corruption bugs. |
| Saturation | A measure of how close your infrastructure is to reaching its maximum capacity limits, tracking memory usage or disk I/O. |
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly assume that purchasing an expensive array of observability software automatically updates their operational workflows. In reality, platform implementation and organizational culture represent two completely distinct dimensions of systems engineering.
Platform implementation focuses on the concrete technical tools, software configurations, and automated testing frameworks that execute your deployments. On the other hand, operational culture dictates how human beings communicate, handle mistakes, and balance speed against safety. A team with the best tools in the world will still fail if a culture of blame prevents them from sharing postmortem insights openly.
Roles & Responsibilities Compared
To understand how these concepts manifest in a real-world enterprise workspace, we can look at the daily duties of different engineering specialists. Each role approaches systems engineering from a unique, complementary angle.
- Platform Engineers: These specialists focus on building and maintaining internal self-service portals, developer platforms, and cloud infrastructure foundations. Their primary goal is lowering the cognitive load for development teams by delivering pre-configured deployment templates.
- Site Reliability Specialists: These engineers embed directly with development groups to optimize application runtime reliability, tune monitoring alerts, and manage error budgets. They bridge the gap between software code and production systems, ensuring the platform scales safely.
- Traditional Infrastructure Operators: These professionals traditionally handle physical hardware provisioning, operating system patching, and baseline network configurations. In modern environments, they manage cloud resources using programmatic automation scripts rather than manual command lines.
Can You Have Both Disciplines?
Modern high-performing technical organizations do not treat platform engineering and site reliability culture as an either-or choice. Instead, these two disciplines complement each other to create a highly efficient software delivery ecosystem.
[SRE Culture & SLO Targets] ---> Guides and Informs ---> [Platform Engineering Tools]
[Platform Engineering Tools] ---> Directs and Standardizes ---> [SRE Culture & SLO Targets]
The platform engineering team builds the underlying automated infrastructure, while the site reliability experts establish the metrics, SLO thresholds, and error budgets that govern those systems. When these two areas align seamlessly, developers can ship high-quality features faster without creating operational chaos. This symbiotic relationship transforms infrastructure from an frustrating bottleneck into a powerful competitive advantage.
Which One Should Your Team Adopt?
Deciding where to focus your engineering resources depends entirely on your company’s current size, technical maturity, and core business goals. Small startups should focus heavily on establishing an automated cultural framework before investing heavily in complex platforms.
| Company Maturity | Primary Strategic Focus | Key Implementation Action |
| Early-Stage Startup | Shared Cultural Foundations | Focus on setting simple SLOs and automating basic deployment flows. |
| Mid-Sized Growth Company | Standardized Tooling & SRE | Embed dedicated reliability engineers into your fastest-growing development teams. |
| Large-Scale Enterprise | Internal Platform Engineering | Build a centralized self-service developer platform to govern thousands of microservices. |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global technology enterprises use automated operational metrics to manage millions of concurrent user sessions without manual intervention. For example, large-scale streaming platforms use sophisticated telemetry to track real-world playback degradation across various geographic regions.
If a localized internet service provider experiences network drops, the streaming system detects the issue instantly through automated SLIs. The infrastructure immediately routes video traffic through alternative delivery networks before viewers notice any buffering. This level of automated traffic management allows digital platforms to protect their customer experience around the clock.
Chaos Engineering Approaches to Resilient Systems
Top-tier cloud enterprises protect their platforms from unexpected infrastructure failures by intentionally injecting faults into live production environments. This advanced practice, known as chaos engineering, involves running automated scripts that randomly shut down server instances or simulate network latency.
[Chaos Engineering Script] ---> Intentionally Kills Pod ---> [Automated System Recovers Pod]
|
v
(Uptime Maintained Silently)
By introducing controlled failures during business hours, engineers can verify whether their automated self-healing mechanisms work correctly. If the platform fails to recover automatically, the team fixes the underlying architectural gap before a real hardware failure occurs. This proactive experimentation transforms hidden vulnerabilities into robust, battle-tested system infrastructure.
Handling Reliability at Massive Scale
Managing distributed microservices that process millions of transactions per minute requires moving past traditional monolithic system architectures. Large e-commerce platforms use dynamic, containerized clusters that automatically scale up or down based on real-time traffic signals.
During massive global shopping events, automated load balancers distribute incoming requests across thousands of isolated computing nodes. If an individual database node gets overwhelmed, the system temporarily throttles non-essential background processes like product recommendations. This strategic degradation protects core checkout workflows, keeping your main revenue streams online.
High-Availability in Fintech Operations
Financial technology and digital payment platforms operate under strict regulations that tolerate zero downtime or data loss. A single minute of downtime can cost millions of dollars and damage consumer trust for years.
To achieve high availability, fintech operations use multi-region database architectures that copy transaction ledgers synchronously across multiple geographic zones. If a natural disaster takes an entire cloud data center offline, automated failover systems reroute payment traffic to a backup facility within milliseconds. This redundant architecture ensures that consumer transactions complete safely without any interruption.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not need to copy the massively complex infrastructure platforms used by trillion-dollar tech giants. Instead, nimble teams apply these core reliability principles efficiently by using managed cloud services and automated third-party tooling.
By leveraging pre-built CI/CD pipelines, container hosting solutions, and basic monitoring dashboards, a small team can easily manage a robust system. They protect their limited engineering time by setting up simple, actionable alerts for critical site failures while ignoring minor non-actionable warnings. This lightweight approach provides early-stage companies with excellent system visibility without overwhelming them with operational overhead.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A frequent mistake companies make is renaming their traditional system administrators “Reliability Engineers” while changing absolutely nothing about their daily habits. If your team spends their entire day responding to alerts and manually restarting servers, you are not practicing modern engineering.
True operational engineering requires dedicating significant time to writing code that prevents alerts from firing in the first place. Treating operations as a continuous on-call firefighting shift burns out your engineers and leaves underlying systemic architectural flaws unfixed.
Mistake 2 — Setting Unrealistic SLOs
Many product managers mistakenly demand 100% availability for their applications because they believe it guarantees a perfect user experience. However, chasing unrealistic uptime targets is incredibly expensive and actively harms your engineering velocity.
Demanding absolute perfection means your developers can never release new features, since every code deployment carries some inherent risk. Smart teams set realistic, user-focused SLOs that leave an appropriate error budget for creative experimentation and rapid feature development.
Mistake 3 — Ignoring Toil Until It’s Too Late
When teams experience rapid growth, they often ignore minor manual chores like manually running database cleanups or generating user reports. Over time, these small tasks accumulate into an unmanageable wall of operational debt that stalls engineering progress.
[Neglected Toil Accumulates] ---> Drains Engineering Time ---> [Zero Progress On Core Reliability]
If your engineers spend more than half their week dealing with repetitive administrative tasks, they cannot focus on building critical automated infrastructure. Organizations must actively track and limit toil to protect their engineering velocity.
Mistake 4 — Skipping Blameless Postmortems
When a production outage occurs, a toxic organizational culture immediately searches for a single human scapegoat to blame. This defensive approach causes engineers to hide mistakes, cover up technical debt, and avoid sharing helpful ideas.
Skipping honest, blameless postmortems prevents your team from uncovering the underlying systemic gaps that allowed the failure to happen. If a single human command line error can take down your entire platform, your system’s architecture is the true failure, not the engineer who typed the command.
Mistake 5 — Monitoring Without Actionable Alerts
Configuring your systems to send a Slack message or email alert for every minor CPU fluctuation creates dangerous alert fatigue. When your engineers receive hundreds of non-actionable notifications every day, they quickly learn to ignore them.
Consequently, when a critical failure message arrives, it gets lost in the noise, resulting in a delayed incident response time. Every alert that pages an engineer must be highly actionable, urgent, and require an immediate human decision to resolve a live issue.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software development teams often design complex application architectures without ever consulting the operations specialists who must maintain them. This disconnect leads to deploying systems that are incredibly difficult to monitor, scale, or troubleshoot in production.
Bringing operational input into the design phase ensures that your applications are built from day one with deep observability, automated scaling, and clean failover capabilities.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining deep visibility into complex distributed systems requires a robust collection of modern monitoring and observability software. Teams use tools like Prometheus to collect granular, real-time time-series metrics from running application clusters.
[Application Clusters] ---> (Prometheus Metrics) ---> [Grafana Dashboards]
These raw data points are then pulled into Grafana to create clear visualization dashboards that display system trends at a glance. For companies looking for a unified, managed solution, platforms like Datadog and New Relic combine application performance monitoring, log aggregation, and network tracing into a single screen.
Incident Management
When a critical system component breaks, incident response teams use specialized communication software to organize their recovery efforts. PagerDuty acts as the primary routing engine for production alerts, analyzing incoming telemetry signals to wake up the correct engineer on call.
The platform manages complex team rotations, escalates unresolved alerts automatically, and tracks response times to improve future incident handling. Using automated incident tooling keeps engineering communications organized, preventing chaotic multi-person triage calls during major platform outages.
CI/CD & Release Engineering
Automating your software delivery pipelines ensures that code updates move smoothly and predictably from a developer’s laptop to production. Teams use Jenkins to run automated test suites, verify security patterns, and compile application code packages.
Once built, GitOps controllers like Argo CD or continuous delivery tools like Spinnaker safely orchestrate deployments across cloud infrastructure. These automation platforms manage complex canary rollouts and monitor live system metrics, automatically rolling back updates if any anomalies emerge.
[Code Commit] ---> [Jenkins Test] ---> [Argo CD Deploy] ---> [Live Production]
Chaos Engineering
Building truly resilient systems requires testing your infrastructure’s self-healing capabilities under real-world failure conditions. Engineers use Chaos Monkey to randomly terminate running container instances within live production environments.
This automated disruption forces applications to maintain availability by dynamically routing traffic around failed infrastructure components. Injecting controlled faults into production exposes hidden architectural flaws early, allowing teams to fix bugs before an actual hardware failure triggers a massive customer outage.
SLO Management
Tracking your long-term reliability metrics against customer expectations requires specialized platform tools to monitor error budgets. Nobl9 connects directly to your existing monitoring data streams to calculate real-time SLO compliance and error budget consumption rates.
The platform alerts engineering teams when a sudden spike in software errors threatens to exhaust their monthly budget. Having clear visual dashboards for operational risk helps product managers and developers make objective, data-driven decisions about feature release speeds.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Starting a successful career in modern systems operations requires building a diverse foundation across software development and systems engineering. First, you must master the Linux command line interface, navigating server directories, managing system permissions, and analyzing raw application logs.
Additionally, you need to learn scripting languages like Python or Go to automate repetitive administrative tasks and write clean infrastructure scripts. Finally, understanding core networking concepts like DNS configuration, TCP/IP protocols, and HTTP status codes is essential for diagnosing complex cloud routing issues.
The Professional Learning Path
Once you master the foundational command line tools, your educational journey shifts toward scalable architecture and cloud infrastructure. Start by learning containerization technologies like Docker to package applications into light, portable units.
Next, dive deep into Kubernetes to understand how to orchestrate, scale, and manage container clusters across cloud networks. From there, explore Infrastructure as Code tools like Terraform to provision entire cloud environments using version-controlled configuration manifests.
[Linux & Scripting Foundations] ---> [Docker Containerization] ---> [Kubernetes Orchestration]
Certifications Worth Pursuing
Industry-recognized technical certifications provide an excellent way to validate your infrastructure skills and accelerate your career. Earning credentials like the Certified Kubernetes Administrator (CKA) or Certified Kubernetes Application Developer (CKAD) proves your ability to manage complex container environments.
Additionally, pursuing advanced cloud certifications like the AWS Certified DevOps Engineer or Google Cloud Professional DevOps Engineer demonstrates your mastery of automated deployments. These rigorous technical exams show employers that you can design, secure, and maintain large-scale production environments.
Educational Resources with Xopsschool
Navigating this extensive educational landscape can feel overwhelming without structured mentorship and hands-on laboratory exercises. This is exactly where partnering with an industry-focused education provider like Xopsschool can transform your professional development.
The platform offers comprehensive training programs built around real-world production architectures, continuous deployment pipelines, and advanced observability setups. Learning from experienced industry mentors helps you move beyond basic theory to gain the practical confidence needed to manage complex enterprise infrastructures.
The Future of Systems Management
AI and Automation in System Optimization
The next generation of systems management relies heavily on embedding machine learning models directly into continuous monitoring pipelines. Artificial intelligence allows systems to analyze massive streams of telemetry data to identify complex anomaly patterns that human operators might miss.
Instead of waiting for a server disk to fill up completely, smart systems predict resource exhaustion days in advance. These automated platforms can even initiate self-healing scripts to reallocate storage or clear cache directories completely independently. This transition toward predictive operations dramatically reduces incident recovery times.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major shift in how modern enterprises structure their internal software development workflows. Instead of requiring every developer to understand complex cloud security and network configurations, dedicated teams build internal developer platforms (IDPs).
[Developer] ---> [Internal Developer Platform (IDP)] ---> [Automated Cloud Infrastructure]
These self-service portals allow developers to provision secure databases, create testing environments, and deploy applications using pre-approved templates. Standardizing these deployment workflows allows organizations to maintain strict security guardrails while accelerating feature release speeds.
Management in Cloud-Native & Kubernetes Environments
As organizations move away from traditional virtual machines toward dynamic serverless containers, orchestration challenges become increasingly complex. Modern cloud-native environments require managing thousands of short-lived microservices that scale up and down in seconds.
Engineers use advanced service mesh architectures to secure internal network communications and manage traffic routing across distributed clusters. Overcoming these orchestration challenges requires building deep expertise in declarative configuration systems, software-defined networking, and automated cluster security policies.
Operational Skills That Will Matter Most
The evolving technological landscape constantly redefines the core competencies required to be a successful systems infrastructure expert. While basic server configuration was once sufficient, modern professionals must develop strong skills in financial cloud cost optimization (FinOps).
Engineers need to analyze utilization data to eliminate wasted cloud spend while maintaining excellent platform performance. Furthermore, mastering deep cross-cluster observability and data trace analysis will remain essential for troubleshooting complex distributed applications.
FAQ Section
- What is the typical salary expectation for a systems reliability specialist?
Compensation packages vary significantly based on geographic location, years of hands-on experience, and specific industry sectors. Senior specialists working in major tech hubs frequently command base salaries ranging from $140,000 to over $200,000 annually. Furthermore, these positions often include valuable equity options, performance bonuses, and comprehensive health benefits that increase total compensation. - How does this discipline differ from traditional system administration?
Traditional system administrators focus primarily on manually configuring hardware, patching operating systems, and responding directly to system alerts. In contrast, modern reliability specialists treat operations as a software engineering problem, dedicating their time to writing automation code. They focus on building scalable systems, setting clear SLO metrics, and eliminating repetitive manual toil permanently. - Can someone transition into this field from a software development background?
Software developers are exceptionally well-positioned to transition into this field because they already possess strong coding and debugging skills. To make the switch successfully, developers simply need to expand their knowledge of networking, operating system internals, and cloud infrastructure. Their software engineering mindset helps them build highly effective automated self-healing scripts for production environments. - What are the most critical metrics to track when starting out?
Beginning teams should focus entirely on tracking the four golden signals: latency, traffic, errors, and system saturation. These fundamental metrics provide a comprehensive snapshot of application health and help identify performance bottlenecks before they impact users. Mastering these basic signals establishes a solid foundation for implementing more advanced observability frameworks down the road. - How much coding knowledge is required for infrastructure operations?
Professionals in this field need a solid grasp of programming concepts to automate modern cloud environments effectively. You should be highly proficient in scripting languages like Python or Bash for daily automation tasks, and understand Go for containerized tools. This coding expertise allows engineers to build reliable deployment pipelines, maintain infrastructure code, and automate complex workflows. - Why are error budgets considered essential for modern product development?
Error budgets provide an objective, data-driven framework for balancing feature innovation speed against baseline platform stability. They remove emotional debates between development squads and operations teams by establishing a clear, agreed metric for deployment risk. As long as your budget remains positive, you can ship features; if it clears out, focus shifts entirely to platform reliability.
Final Summary
Maintaining exceptional platform reliability requires moving past fragmented legacy engineering pipelines and embracing automated, cross-functional collaboration frameworks. By treating infrastructure as a core software engineering challenge, modern enterprises can balance rapid feature innovation with rock-solid system stability. Embracing essential metrics like error budgets, clear SLO targets, and comprehensive observability transforms operations from an unpredictable firefighting exercise into a predictable strategic advantage. Ultimately, building a sustainable engineering culture that automates repetitive toil ensures your systems scale smoothly alongside your business. If you are ready to master these advanced technical frameworks and accelerate your engineering career, begin your learning journey today with the structured professional courses at Xopsschool.