Imagine a major digital payment processing pipeline collapsing during the peak hours of a global shopping festival. While frustrated customers watch transaction screens freeze, engineers frantically bounce between isolated software tools, attempting to pinpoint the root cause of the system failure. This chaotic scenario highlights the exact operational bottlenecks that crush organizational momentum when cross-functional pipelines remain deeply fractured and disconnected.
Modern software systems demand an integrated paradigm that unifies specialized disciplines like development, security, data operations, and machine learning into a single cohesive delivery system. Incorporating comprehensive strategies for this unified framework allows scaling tech enterprises to deploy software rapidly while maintaining optimal stability and robust security protocols. Transitioning to this holistic operational strategy eradicates departmental friction, speeds up feature releases, and ensures that cross-functional infrastructure remains highly resilient under massive transaction volumes.
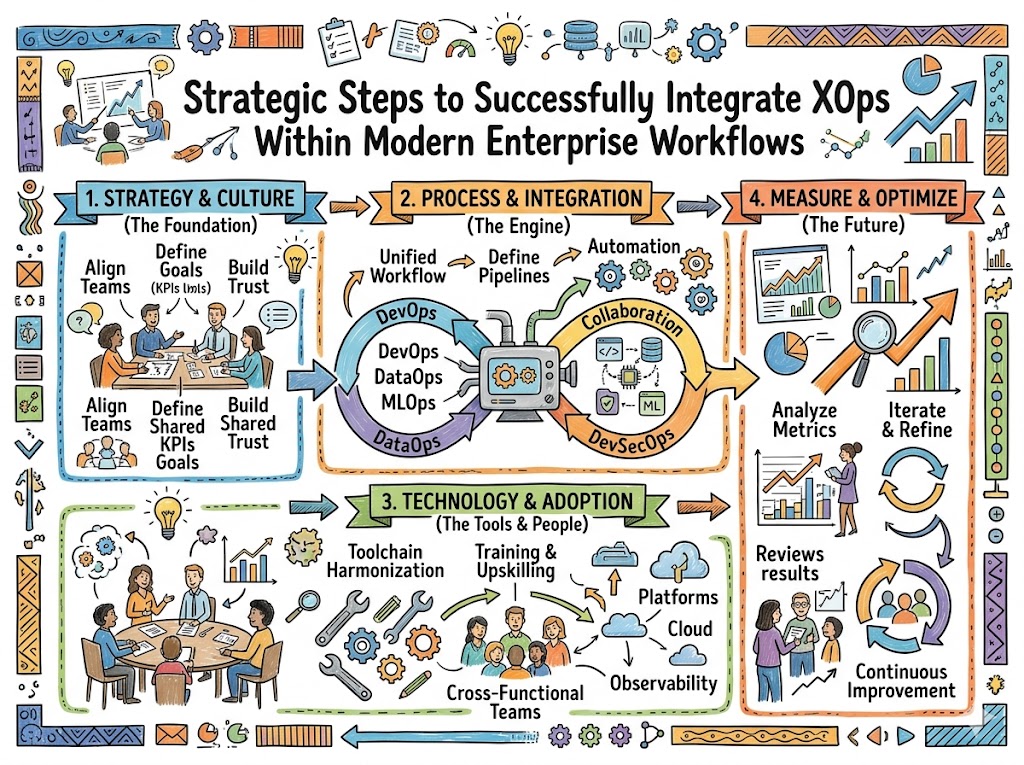
This deeply researched guide explores the architectural blueprints, foundational pillars, and tactical roadmaps required to integrate cross-functional operations within your corporate structure. Readers will learn about historical infrastructure shifts, core performance metrics, platform implementations, and strategies to avoid devastating deployment pitfalls.
Building a resilient, high-velocity infrastructure requires deep expertise, and teams can accelerate this transformation journey by accessing the premium enterprise learning tracks provided at Xopsschool, where professionals master advanced systems automation and modern workflow orchestration.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise tech structures relied heavily on isolated, distinct departments that operated independently inside rigid functional siloes. Developers focused solely on writing new code and pushing feature updates outward as quickly as possible. Meanwhile, separate operations teams carried the heavy responsibility of maintaining production server uptime and handling sudden system crashes.
Consequently, this profound operational disconnect created an environment of mutual frustration and constant finger-pointing during unexpected infrastructure failures. Code deployments frequently stalled because the target deployment environments varied dramatically from the local setups used during initial development. These early industrial bottlenecks ultimately proved that splitting creation from maintenance introduces immense delivery friction and limits corporate growth.
Moving Toward Unified Workflow Automation
As enterprise applications grew increasingly complex, forward-thinking organizations realized that manual handoffs between siloed teams were no longer sustainable. The industry began moving rapidly toward automated delivery pipelines that bridged the deep gap between code creation and live infrastructure management.
By automating code testing, package integration, and environment provisioning, companies successfully eliminated the unpredictable human errors that plagued manual setups. Breaking down these historical departmental walls allowed engineers to collaborate continuously throughout the entire lifecycle of an application. This critical evolution shifted the corporate focus from slow, manual resource management toward fluid, automated software delivery systems.
Global Expansion Across Commercial Ecosystems
The remarkable success of early automated delivery systems sparked a massive movement across the entire global commercial ecosystem. Large-scale tech enterprises, financial institutions, and e-commerce platforms quickly realized they needed to apply these collaborative automation principles universally.
As a result, specialized operational frameworks began expanding into fields like security engineering, data pipeline management, and artificial intelligence model deployments. This widespread expansion permanently altered how modern corporations design, protect, and optimize their digital assets at scale. Today, cross-functional orchestration serves as the foundational backbone for any enterprise aiming to survive and thrive in a digital-first economy.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management establishes a unified, feedback-driven architecture where system components communicate continuously across all stages of delivery. This modern structural layout depends heavily on real-time data loops that feed production insights directly back into the early design phase.
[Design & Plan] ──> [Automated Test] ──> [Secure Deploy] ──> [Observe & Optimize]
▲ │
└────────────────────── Real-Time Feedback Loop ──────────────────┘
By structuring infrastructure around clear, visible pipelines, organizations ensure that every single systemic change undergoes automated validation. This continuous loop prevents hidden configuration drift and guarantees that your production environments match your pre-production baselines exactly. Consequently, the core architecture remains robust, predictable, and highly adaptable to rapidly changing market demands.
Daily Tasks of Systems Coordinators
Systems coordinators spend their daily working hours designing and maintaining the automated scaffolding that keeps corporate pipelines moving smoothly. Instead of manually configuring physical hardware, these specialists write declarative code to provision cloud resources and manage cluster scaling policies.
They actively review pipeline metrics, tune automated testing suites, and optimize the security checkpoints embedded within deployment workflows. When unexpected alerts trigger, coordinators conduct rapid diagnostic reviews to resolve the underlying systemic anomalies before end users experience any service degradation. Their daily efforts keep human intervention minimal, allowing development teams to ship software updates with maximum speed and absolute confidence.
Localized Control vs. Broad System Architecture
Managing modern environments requires a clear understanding of the delicate balance between localized control and broad system architecture. Localized control focuses on optimizing individual microservices, fine-tuning single databases, or adjusting specific pipeline segments for speed.
In sharp contrast, broad system architecture analyzes how these disparate components interact, communicate, and scale together as a singular cohesive entity. Focusing exclusively on localized metrics can lead to overall system failures if the broader intersecting pathways suffer from hidden network bottlenecks. Therefore, successful enterprises prioritize holistic architectural visibility to ensure that individual changes never compromise the stability of the global ecosystem.
The Efficiency Mindset
Transitioning to an advanced operational model requires a profound cultural shift centered entirely around a long-term efficiency mindset. This specific engineering philosophy dictates that teams must treat operational stability as a core feature of the software itself rather than an afterthought.
Instead of applying temporary fixes to recurring infrastructure issues, engineers actively dedicate time to building permanent, automated solutions. This proactive cultural approach encourages teams to welcome manageable calculated risks while keeping an unyielding focus on long-term architecture health. By prioritizing sustainability over rushed, short-term fixes, organizations build highly resilient environments that require significantly less manual maintenance over time.
The 7 Core Principles of XOps
1. Embracing Risk and Managing Variability
Modern systems engineering operates on the fundamental truth that achieving absolute, 100% system uptime is both economically impractical and structurally restrictive. Trying to eliminate every single microscopic possibility of failure slows down feature innovation and burns through valuable engineering hours needlessly.
Instead, progressive organizations focus on embracing acceptable, calculated risks by defining clear operational tolerances for system degradation. By acknowledging that minor failures will inevitably happen, teams can design fault-tolerant systems that degrade gracefully without causing complete business outages. This pragmatic approach balances the urgent need for rapid software innovation with the baseline requirement of system stability.
2. Establishing Service Level Objectives (SLOs)
Organizations must ground their reliability metrics in clear, user-centric data by establishing strict Service Level Objectives. These measurable targets define the precise level of performance and availability that an application must maintain to keep end users satisfied.
SLI (Actual Performance) ───> Compared Against ───> SLO (Target Reliability)
By linking technical performance directly to business expectations, teams can easily determine whether their systems are operating within acceptable parameters. These objectives serve as the ultimate truth source for engineering teams, removing emotion from discussions about stability. Maintaining clear, quantitative goals ensures that both business stakeholders and infrastructure engineers remain completely aligned regarding system performance priorities.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, manual, and non-constructive operational tasks that scale linearly as your server footprint expands over time. Left unchecked, manual interventions like running manual database backups or manually restarting stuck processes drain engineering creativity and stunt productivity.
Strategic operations demand that teams systematically identify these repetitive manual workflows and actively engineer them away using automated software scripts. Eliminating this operational drag frees up specialists to focus their unique talents on proactive architecture design and system optimization. Reducing manual friction ensures that the organization can scale its infrastructure massively without requiring a linear increase in engineering headcount.
4. Monitoring & Observability Across the Pipeline
True operational control requires deep, end-to-end visibility across every single layer of your software delivery pipeline and production environments. Monitoring informs teams when a specific component fails, while advanced observability allows engineers to understand exactly why that failure occurred deep within complex distributed networks.
[User Request] ──> [API Gateway] ──> [Microservices] ──> [Database Cluster]
│ │ │ │
└──────────────────┴── Labeled Metrics & Traces ─────────┴──────────> [Observability Engine]
By tracking telemetry data across development, security, and deployment pipelines, organizations eliminate dangerous operational blind spots before they impact users. This continuous streams of structural data enables teams to spot subtle performance regressions early and optimize data paths for maximum efficiency. Maintaining comprehensive observability ensures that your engineering groups can make informed, data-driven decisions during complex architectural upgrades.
5. Automation Over Manual Coordination
Relying on manual human coordination to pass software updates between separate departments introduces severe delays and invites catastrophic configuration mistakes. Modern infrastructure frameworks firmly prioritize smart software automation over human-driven gatekeeping at every major stage of the delivery lifecycle.
Whether provisioning complex cloud infrastructure, running security vulnerability scans, or executing canary deployments, software engines should handle the heavy lifting. This engineering-first approach ensures that repetitive processes remain perfectly uniform, verifiable, and completely auditable. By replacing manual workflows with declarative code, companies achieve a level of operational agility that manual coordination simply cannot match.
6. Release Engineering and Deployment Stability
Release engineering is a specialized discipline focused entirely on the safe, predictable, and highly consistent delivery of software artifacts into production. Teams must treat the deployment pipeline as a critical production system that requires rigorous testing, version control, and continuous optimization.
Implementing modern release strategies like blue-green deployments or progressive feature flags allows companies to test new updates on isolated user segments safely. If a new code release exhibits performance anomalies, automated rollbacks should trigger instantly to restore the stable baseline environment. Prioritizing deployment stability allows enterprises to innovate rapidly without risking the core operational availability that customers depend on daily.
7. Simplicity in Network Architecture
As systems grow over time, they naturally accumulate immense structural complexity, creating hidden failure points and confusing data pathways. Progressive systems engineering fights this natural clutter by making a conscious, continuous effort to maintain absolute simplicity in network architecture.
Keeping infrastructure minimal, clean, and highly modular directly reduces the overall attack surface and simplifies day-to-day diagnostic troubleshooting. Engineers should avoid over-engineering solutions and always choose the cleanest, most direct path to achieve the desired technical outcome. A simple, well-documented architecture remains far easier to secure, monitor, automate, and scale efficiently across global commercial markets.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the precise differences between SLAs, SLOs, and SLIs is absolutely essential for managing modern infrastructure effectively. These three metrics form the core foundation of data-driven reliability management across all large-scale tech enterprises.
- SLA (Service Level Agreement): The high-level legal and commercial commitment made directly to external customers, defining what happens if service commitments fail.
- SLO (Service Level Objective): The internal, metric-driven target that engineering teams must hit to ensure the system remains compliant with the external SLA.
- SLI (Service Level Indicator): The precise, real-time quantitative measurement of current performance, tracking the exact compliance percentage of your SLO.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or system instability that an organization is willing to tolerate over a specific time window. For instance, if your established SLO dictates a 99.9% uptime target, your team possesses a clear 0.1% error budget for allowable risks.
This metric serves as a dynamic, objective referee that effectively balances fast-paced feature innovation with baseline system safety. When the error budget is entirely full and healthy, developers can aggressively push new features and experimental code updates into production. However, if unexpected outages drain the budget completely, feature releases halt instantly, and the entire team shifts focus exclusively to system stabilization.
Toil — The Silent Productivity Killer in Infrastructure
Toil is the repetitive, manual, and administrative work that offers no long-term structural value to your engineering ecosystem. It is easily identified by its lack of engineering creativity, its repetitive nature, and the fact that it scales directly alongside system growth.
To eliminate this silent productivity killer, teams must accurately calculate the percentage of time engineers spend on manual operations versus proactive engineering tasks. Organizations should set a strict internal rule dictating that at least 50% of an engineer’s time must remain dedicated to building automated software solutions. Systematically automating away these repetitive tasks prevents operational debt from accumulating and ensures your engineering velocity remains high.
Incident Management & Postmortems
When severe production outages occur, modern organizations lean heavily on structured incident management protocols to restore baseline services rapidly. The primary objective during an active incident is resolving the immediate user-facing issue, not spending time looking for who made the mistake.
Once the system returns to a stable state, teams must conduct comprehensive, blameless postmortems to analyze the true root cause of the failure. A blameless culture ensures that engineers feel entirely safe reporting technical mistakes and identifying deep systemic flaws without fear of professional punishment. Transforming these operational failures into detailed, documented lessons allows organizations to continuously harden their infrastructure against future disruptions.
Capacity Planning
Capacity planning is the highly analytical practice of forecasting future business growth and preparing core computing infrastructure well ahead of demand spikes. Teams must regularly analyze historical traffic trends, compute usage patterns, and seasonal business cycles to predict resource exhaustion accurately.
By mapping these growth vectors, companies can implement automated scaling rules and provision cloud resources efficiently without overpaying for idle standby hardware. Proper capacity planning prevents sudden performance degradation when marketing campaigns pull massive waves of new users onto the platform simultaneously. Looking forward systematically ensures that your foundational infrastructure effortlessly supports corporate growth instead of acting as a bottleneck.
The Four Golden Signals of Pipeline Performance
To maintain complete operational clarity, engineering teams must monitor the Four Golden Signals of system performance continuously. These critical metrics provide an immediate, data-driven health check for any distributed software architecture.
| Signal | Definition | Core Measurement Metric |
| Latency | The exact time it takes to service a request | Milliseconds per API call |
| Traffic | The total demand being placed on the system | Requests per second |
| Errors | The rate of requests that fail explicitly or implicitly | Percentage of 5xx HTTP responses |
| Saturation | The overall fullness of the system core resources | Memory and CPU utilization percentages |
Monitoring these four intersecting signals allows teams to spot early performance degradation and resolve infrastructure stress before it transforms into a major user-facing outage.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly believe that integrating modern operations simply requires buying expensive monitoring software or building automated pipelines. However, technical platform implementation and organizational culture represent two entirely different sides of the same transformational coin.
Platform implementation focuses squarely on the tools, infrastructure code, and technical frameworks used to execute automation across the enterprise. In contrast, culture represents the shared engineering philosophy, open communication styles, and collective accountability models embraced by your human workforce. Tools are completely useless if teams remain trapped in siloed thinking and refuse to cooperate transparently during major system architectural changes.
Roles & Responsibilities Compared
To build an efficient delivery model, companies must clearly define the day-to-day duties and operational boundaries across distinct engineering groups. Misaligned expectations regarding responsibilities often lead to neglected infrastructure tasks and severe operational gaps.
- Platform Implementation Engineers:
- Design, build, and maintain the self-service deployment platforms used by internal development groups.
- Write declarative infrastructure-as-code scripts to provision underlying compute clusters safely.
- Optimize centralized logging, tracing, and metric collection tools across the entire enterprise.
- Culture-Focused Systems Specialists:
- Facilitate blameless postmortem sessions and drive cross-departmental alignment on performance metrics.
- Help software development teams define realistic, user-centric Service Level Objectives.
- Advocate for continuous improvement practices and champion the elimination of manual operational toil.
Can You Have Both Disciplines?
Rather than viewing technical platforms and cultural frameworks as competing concepts, modern organizations treat them as deeply complementary philosophies. A robust automated platform acts as the technical enabler that allows a collaborative engineering culture to scale across massive commercial ecosystems.
Simultaneously, a healthy, transparent culture ensures that teams use the automated platform responsibly and continuously optimize it for long-term stability. Coexisting harmoniously, these two disciplines reinforce each other, allowing organizations to achieve exceptional delivery speed without sacrificing system safety. Blending structural automation with clear behavioral alignment creates a highly resilient organization capable of handling complex digital transformations.
Which One Should Your Team Adopt?
Choosing where to focus your initial transformation efforts depends heavily on your current organizational size, technical debt, and engineering maturity.
- Early-Stage Startups: Focus heavily on cultural principles, establishing shared accountability, defining basic SLOs, and keeping network setups simple without installing massive tooling suites.
- Mid-Sized Growing Scaling Enterprises: Begin investing rapidly in standardized platform implementations to automate environments and eliminate manual toil before it blocks delivery velocity.
- Large Mature Global Corporations: Must aggressively execute both strategies simultaneously, using unified platforms to enforce security compliance while driving cultural alignment to prevent departmental silos.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software enterprises track thousands of continuous metrics to maintain peak performance across highly distributed microservice ecosystems. These industry leaders use real-time streaming dashboards that aggregate telemetry data from millions of concurrent user sessions globally.
By analyzing subtle changes in latency and error rates across different geographic zones, their monitoring systems can automatically isolate faulty server regions. This data-driven approach allows tech giants to deploy code hundreds of times a day while keeping global availability pristine. Relying on hard, quantitative system data removes guesswork, allowing engineering teams to optimize performance where it matters most to users.
Chaos Engineering Approaches to Resilient Systems
Top-tier streaming platforms and cloud providers ensure system resilience by actively injecting controlled failures into live production environments. This proactive architectural practice, known as chaos engineering, involves intentionally shutting down server nodes or introducing network latency to test system self-healing capabilities.
[Chaos Engine Injects Failure] ──> [System Detects Anomaly] ──> [Auto-Healing Triggers] ──> [Uptime Maintained]
By intentionally breaking components during normal business hours, engineers can uncover hidden design flaws and fragile dependencies before real outages occur. This disciplined approach shifts teams away from a reactive firefighting mindset toward a proactive engineering posture. Chaos engineering proves that the absolute best way to guarantee system reliability is to actively practice surviving unexpected operational failures.
Handling Reliability at Massive Scale
Hyper-scale web platforms handle hundreds of millions of concurrent transactions daily by architectural engineering that eliminates single points of failure completely. These distributed environments rely on intelligent global load balancers that automatically route user traffic away from degraded database clusters.
They utilize advanced caching layers and localized microservices that operate entirely independently, ensuring that a single component failure never collapses the entire application. When system saturation reaches predefined thresholds, automated provisioning engines immediately spin up additional cloud resources to distribute the operational load. Managing reliability at this massive scale requires complete commitment to continuous automation, absolute code uniformity, and deep observability across all data paths.
High-Availability in Fintech Operations
Modern financial technology networks operate under strict regulatory standards and zero-tolerance mandates for transactional downtime or data corruption. A single minute of latency within a banking API can result in millions of dollars of lost revenue and severe legal penalties.
To maintain high availability, fintech operations implement real-time transactional monitoring systems that analyze payment paths for security anomalies instantly. They utilize synchronous multi-region data replication to ensure that if an entire data center goes dark, financial records remain completely safe and accessible. Combining strict security controls with automated failover mechanisms allows these high-stakes platforms to deliver seamless consumer experiences while protecting sensitive financial ecosystems.
Scaled-Down but Essential Systems for Startups
Early-stage companies often lack the massive engineering budgets and vast headcount enjoyed by global tech enterprises. However, startups can still apply core operational principles highly efficiently by focusing exclusively on essential automation and clean architectural baselines.
By utilizing managed cloud services and lightweight open-source monitoring tools, small teams can easily track the four golden signals without massive overhead. Automating basic code linting, vulnerability scanning, and application deployments prevents small engineering groups from accumulating catastrophic technical debt early on. Implementing these scalable workflows early ensures that the startup’s digital infrastructure can support rapid business scaling without requiring a chaotic architectural rewrite later.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A catastrophic mistake many corporate leaders make is assuming that modern systems engineering simply means setting up a 24/7 on-call rotation. Forcing engineers to constantly answer urgent alerts without giving them time to fix the root cause creates a toxic, reactive environment.
This discipline is fundamentally about proactive software engineering, building automated systems that prevent incidents from occurring in the first place. When a team spends all its time firefighting, it accumulates massive operational debt and stalls strategic development completely. Organizations must ensure that on-call engineers possess the structural authority and dedicated time required to automate away recurring system alerts permanently.
Mistake 2 — Setting Unrealistic SLOs
In a misguided attempt to impress customers, leadership teams often demand absolute, unyielding perfection, such as setting a 100% system uptime target. This unrealistic goal creates severe friction because shipping innovative features inherently introduces a degree of operational risk into live environments.
Demanding perfect stability forces engineering groups to slow down deployments dramatically, perform tedious manual reviews, and become overly risk-averse. This operational gridlock burns out talented engineers and allows nimbler competitors to dominate the market rapidly. Teams must establish pragmatic, user-centric objectives that leave a healthy error budget for continuous software experimentation and fast-paced feature iteration.
Mistake 3 — Ignoring Toil Until It’s Late
When companies grow rapidly, teams often ignore repetitive manual tasks, choosing instead to focus exclusively on launching new consumer-facing features. This short-sighted approach allows manual toil to accumulate quietly behind the scenes until it completely consumes your engineering workforce’s daily capacity.
Eventually, engineers spend their entire working weeks manually running scripts, fixing broken configurations, and managing environments by hand. This heavy operational drag brings core product development to a crawl and severely damages organizational morale. Successful tech enterprises treat manual toil as a critical system bug that must be identified, tracked, and aggressively automated away before it paralyzes engineering momentum.
Mistake 4 — Skipping Blameless Postmortems
When a major production outage causes financial damage, traditional corporate cultures often seek a single individual to blame and punish. This toxic approach causes engineers to actively hide system mistakes, cover up configuration errors, and avoid taking calculated risks altogether.
Skipping blameless reviews ensures that the true, underlying architectural flaws remain unaddressed within your network, virtually guaranteeing that the incident will happen again. Organizations must understand that human errors are symptoms of poor system design, not the root cause of infrastructure failure. Establishing an authentic blameless postmortem practice allows teams to collaborate honestly and build robust automated guardrails that make human mistakes impossible to repeat.
Mistake 5 — Monitoring Without Actionable Alerts
Many infrastructure groups configure their monitoring platforms to send automated notifications for every single minor metric fluctuation or temporary CPU spike. This undisciplined setup floods engineering communication channels with hundreds of non-critical messages daily, leading directly to severe alert fatigue.
When critical, catastrophic system failures actually occur, engineers often miss the notification because they have become completely desensitized to the constant noise. Organizations must enforce a strict rule: every single automated alert must be meaningful, urgent, actionable, and accompanied by a clear troubleshooting playbook. Non-actionable data should stay on quiet diagnostic dashboards instead of waking up engineers in the middle of the night.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software development groups frequently design complex application architectures in complete isolation before tossing the finished code over the wall to operations. This fragmented process results in systems that run perfectly on a developer’s local machine but fail miserably under real-world production traffic.
Discovering that an application is impossible to monitor, scale, or secure after it launches introduces immense engineering rework and massive delays. To avoid this costly mistake, companies must involve operational specialists from day one of the initial product design phase. Bringing operational insights into early planning sessions ensures that new software features are built from the ground up to be resilient, highly observable, and easily automated.
Essential Infrastructure Tools & Technologies
To execute a modern operations strategy successfully, enterprises must select and integrate a unified suite of infrastructure technologies. These tools automate data collection, manage application releases, and protect systems from unexpected downtime.
Monitoring & Observability
Maintaining complete system visibility requires tools that collect metrics, aggregate application logs, and trace individual user journeys across distributed networks. Open-source platforms like Prometheus extract time-series data efficiently, while Grafana visualizes these complex data streams via customizable real-time dashboards.
Enterprises seeking managed solutions leverage platforms like Datadog or New Relic to monitor multi-cloud infrastructure through a single pane of glass. These technologies allow engineering groups to spot performance regressions instantly and identify network bottlenecks before they transform into outages. Maintaining a robust observability stack ensures that your team makes engineering decisions based on hard data rather than intuition.
Incident Management
When critical systems degrade, teams rely on automated incident response platforms to coordinate emergency workflows and alert the correct on-call engineers. Tools like PagerDuty integrate directly with monitoring engines to transform incoming technical alerts into structured, trackable incident tickets instantly.
These platforms manage complex team escalation paths, spin up secure communication bridges, and ensure that the right specialists receive urgent notifications immediately. Using automated incident management systems reduces your mean time to resolution (MTTR) dramatically by eliminating manual coordination delays during high-stress outages. Hardening your response workflows ensures that your enterprise handles production emergencies calmly, logically, and with minimal confusion.
CI/CD & Release Engineering
Automating the software delivery pipeline requires powerful continuous integration and continuous deployment engines that test and deploy code changes safely. Traditional automation tools like Jenkins provide massive plugin ecosystems to orchestrate highly customized build workflows across legacy infrastructure environments.
Modern, cloud-native enterprises adopt GitOps-driven deployment engines like Argo CD or Spinnaker to sync infrastructure states with version-controlled repositories automatically. These technologies ensure that every single code deployment is repeatable, fully auditable, and easily reversible if production anomalies occur. Standardizing on advanced release engineering platforms allows companies to ship high-quality features continuously while maintaining absolute system stability.
Chaos Engineering
Hardening distributed environments against unexpected cloud outages requires specialised software designed to introduce controlled system failures safely. Tools like Chaos Monkey pioneered this domain by systematically terminating live production server nodes to validate system self-healing capabilities.
Modern engineering teams utilize advanced platforms to simulate complex real-world anomalies like network latency spikes, disk corruption, and regional cloud data center failures. Injecting these failure vectors under controlled conditions allows developers to find hidden flaws in their architecture before real disasters strike. Practicing chaos engineering transforms system resilience from a theoretical goal into a continuous, measurable metric.
SLO Management
Tracking service reliability against user-centric expectations requires specialized platforms that calculate real-time error budgets and compliance rates. Technologies like Nobl9 connect directly to existing monitoring systems, translating raw technical metrics into actionable Service Level Objectives.
These tools provide clear visual warnings when an application’s error budget drains too quickly, alerting product managers to slow down feature releases. Utilizing dedicated SLO management systems removes subjectivity from engineering priorities, establishing a clear data-driven balance between innovation velocity and system safety. Centralizing these reliability metrics ensures that all business stakeholders remain perfectly aligned regarding operational risk limits.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Breaking into this highly competitive engineering domain requires building a deep, comprehensive foundation in both software development and systems engineering. Aspiring specialists must master terminal commands, advanced shell scripting, and core operating system concepts like process management and file systems.
You must develop a strong working knowledge of networking protocols, security standards, and modern containerization technologies like Docker and Kubernetes. Additionally, learning to write clean code in programming languages like Python or Go is absolutely essential for building modern automation scripts. Combining deep software coding literacy with traditional systems administration knowledge creates a highly versatile engineer capable of managing global enterprise environments.
The Professional Learning Path
Transitioning from a traditional technology role into a senior infrastructure architect requires a structured, step-by-step educational journey.
[Systems Admin / Dev] ──> [Cloud Automation Engineer] ──> [Reliability Architect]
Engineers typically start by mastering local infrastructure environments, learning to configure web servers, databases, and local firewalls manually. Next, professionals move into cloud automation, learning to manage distributed virtual networks and write infrastructure-as-code blueprints using tools like Terraform.
From there, the learning path focuses deeply on advanced reliability engineering, master clustering orchestration, designing multi-region failovers, and defining enterprise SLOs. Continuous education and hands-on laboratory experimentation are the absolute keys to moving smoothly up this professional ladder.
Certifications Worth Pursuing
While practical hands-on experience is incredibly valuable, obtaining industry-recognized professional certifications helps validate your specialized infrastructure expertise to global enterprises. Earning credentials like the Certified Kubernetes Administrator (CKA) proves your deep technical capability to manage complex containerized clusters at scale.
Advanced cloud architecture certifications from major providers like AWS, Google Cloud, and Microsoft Azure demonstrate your ability to design secure, fault-tolerant global systems. Additionally, pursuing specialized certifications in site reliability engineering or modern delivery automation provides a significant competitive advantage in the corporate job market. These credentials show a clear commitment to mastering the modern, cross-functional automation practices that scaling enterprises demand today.
Educational Resources with Xopsschool
Navigating this vast technical landscape can feel completely overwhelming for individual engineers and expanding corporate IT departments alike. To streamline your educational path, professionals can access the deeply structured training curriculums and immersive laboratory environments designed by Xopsschool.
The platform offers comprehensive, mentor-led programs that cover everything from basic terminal automation to advanced multi-cloud architecture and chaos engineering strategies. Students gain valuable hands-on experience by building real-world deployment pipelines, configuring observability platforms, and resolving live production system simulations. Investing in these structured enterprise learning resources allows engineering teams to acquire the modern operations skills required to lead digital transformation initiatives successfully.
The Future of Systems Management
AI and Automation in System Optimization
The next generation of systems engineering will be shaped profoundly by the integration of artificial intelligence and machine learning models within delivery pipelines. Future monitoring platforms will not simply wait for a metric to cross a hard threshold before sending an automated alert to engineers.
Instead, intelligent anomaly detection engines will continuously analyze vast streams of telemetry data to predict infrastructure failures well before they happen. These smart systems can automatically adjust resource allocations, optimize database query paths, and trigger precise self-healing scripts to resolve performance regressions instantly. Integrating AI within your operational framework allows tech enterprises to achieve unprecedented levels of systemic efficiency while reducing manual debugging hours dramatically.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly emerging as the natural evolution of infrastructure management, focused entirely on optimizing the internal developer experience. Instead of forcing software developers to master complex cloud networking and cluster configurations, platform teams build centralized, self-service internal developer portals.
[Developer Portal] ──> [Standardized Golden Paths] ──> [Automated Secure Cloud Deployment]
These portals provide standardized, fully compliant templates that allow software creation groups to provision secure environments and deploy code independently with a single click. This structural evolution removes delivery bottlenecks completely while ensuring that enterprise security policies and architectural standards remain perfectly enforced. Shifting toward self-service platform infrastructure enables organizations to accelerate feature velocity dramatically while maintaining complete operational control.
Management in Cloud-Native & Kubernetes Environments
As enterprises migrate universally toward dynamic containerized architectures, managing system reliability requires an entirely new set of orchestration skills. Traditional monitoring practices fall short when dealing with thousands of ephemeral containers that spin up and disappear within seconds across global networks.
Future systems specialists must master advanced cloud-native service meshes to manage localized microservice communication, security encryption, and traffic routing dynamically. Organizations must build highly adaptable delivery pipelines capable of scaling compute resources fluidly across hybrid and multi-cloud environments seamlessly. Navigating these complex containerized ecosystems requires an unyielding commitment to declarative automation, immutable infrastructure baselines, and deep, real-time observability.
Operational Skills That Will Matter Most
As technology landscapes continue to shift rapidly, the specific technical skills that define an elite systems specialist are evolving accordingly. Modern organizations are placing immense premium value on financial cost optimization engineering, requiring specialists to build highly cost-efficient cloud architectures.
Deep data observability skills will also become incredibly critical, as engineers must trace complex asynchronous data paths across massive, globally distributed AI modeling pipelines. Furthermore, the ability to design secure-by-default pipelines that weave compliance checks seamlessly into automated deployment workflows will remain a top corporate priority. Professionals who combine deep technical automation mastery with strong financial acumen and analytical communication skills will lead the industry forward.
FAQ Section
- What is the primary difference between traditional DevOps and the modern integrated XOps framework?Traditional DevOps focuses primarily on breaking down the historical barriers between software development and IT operations teams to speed up code delivery. In sharp contrast, the modern integrated XOps framework expands these collaborative automation principles universally across all specialized operational domains, including security, data engineering, and artificial intelligence.
- How does an engineering team calculate and monitor its system error budget effectively over time?An error budget is calculated by subtracting your target Service Level Objective percentage from absolute perfection, which is 100%. For example, a 99.9% availability objective leaves a clear 0.1% error budget, which teams track continuously using automated observability tools that measure live system performance indicators against user-centric expectations.
- Why are blameless postmortems considered so vital for long-term corporate infrastructure stability?Blameless postmortems focus entirely on discovering how the system architecture failed rather than punishing the individual engineer who made a mistake. This transparent culture encourages engineering teams to report technical flaws honestly, allowing the organization to build robust automated guardrails that prevent the same incident from ever happening again.
- What are the most common entry-level skills required to land a professional role in systems engineering?Aspiring specialists must build a strong foundational command of terminal configurations, shell scripting languages like Bash, and programming languages like Python or Go. Additionally, candidates must possess a solid understanding of cloud-native computing, modern networking protocols, security baselines, and container orchestration platforms like Docker and Kubernetes.
- How does manual operational toil impact overall engineering velocity and corporate product innovation?Manual toil consists of repetitive, non-constructive administrative tasks that scale linearly alongside server footprint expansion without adding long-term structural value. Left unautomated, these manual interventions completely drain engineering capacity, consume valuable innovation hours, lower team morale, and introduce severe risk of human configuration errors.
- What salary trends can certified systems automation experts expect to find in the current corporate market?Certified systems automation experts remain in exceptionally high demand globally as enterprises rapidly modernize their legacy infrastructure networks. Experienced professionals who hold recognized cloud architecture and container orchestration credentials command premium compensation packages that sit significantly higher than traditional software administration averages.
Final Summary
Maintaining exceptional digital infrastructure health requires a continuous, data-driven commitment to balancing fast-paced feature innovation with absolute systemic resilience. By systematically embedding user-centric Service Level Objectives, eliminating manual operational toil, and cultivating a transparent, blameless engineering culture, organizations can successfully future-proof their delivery frameworks. Implementing these cross-functional practices allows scaling tech enterprises to deploy software updates rapidly, secure complex data paths seamlessly, and survive unexpected production outages with complete confidence.
The future of commercial enterprise technology belongs entirely to organizations that transform their infrastructure operations from a manual, reactive firefighting chore into a highly automated, proactive strategic asset. To accelerate this critical transition and build a world-class engineering workforce, corporate teams can partner with the advanced educational programs provided by [Xopsschool].