Introduction
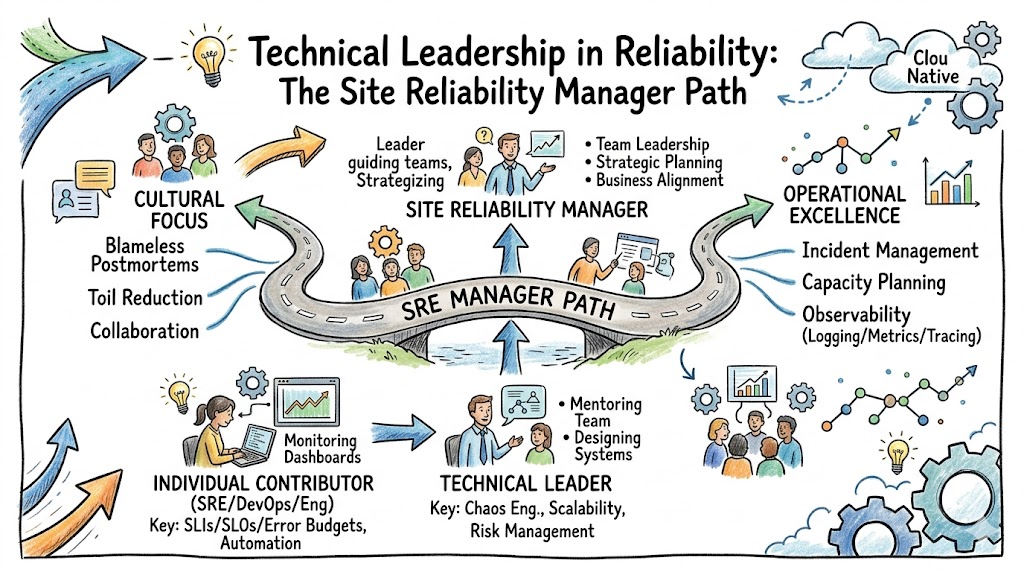
Modern enterprise environments demand a bridge between complex engineering and strategic management, which is where the Certified Site Reliability Manager role becomes essential. This guide assists professionals in navigating the shift from individual contributors to technical leaders who oversee resilient, scalable systems. By focusing on the intersection of DevOps, platform engineering, and reliability, we help you understand how this credential impacts your trajectory at Sreschool. Navigating career growth in a cloud-native world requires clear milestones, and this roadmap ensures you make informed decisions about your professional development and educational investments.
What is the Certified Site Reliability Manager?
The Certified Site Reliability Manager represents a professional standard for those leading the cultural and technical aspects of reliability engineering. It exists because managing production systems at scale requires more than just coding skills; it necessitates a deep understanding of risk management and incident response. This designation emphasizes real-world applications such as defining error budgets and managing technical debt rather than just memorizing theoretical frameworks. Consequently, it aligns perfectly with modern engineering workflows and enterprise practices where uptime is directly tied to business revenue and customer trust.
Who Should Pursue Certified Site Reliability Manager?
Experienced software engineers and SREs looking to move into leadership roles will find this path highly beneficial. Additionally, cloud professionals and platform engineers who want to formalize their management skills can use this to validate their expertise. Engineering managers who already lead technical teams can also leverage this certification to better understand the granular requirements of high-availability systems. Whether you are working within the tech hubs of India or for a global multinational, this certification provides the universal language needed to lead reliability initiatives.
Why Certified Site Reliability Manager is Valuable and Beyond
The demand for leaders who can balance rapid feature deployment with system stability continues to grow as organizations move toward complex microservices. This role ensures longevity in your career because it focuses on core principles like observability and automation that remain constant even as specific tools change. Furthermore, enterprises adopt SRE principles to manage their digital transformation, making these skills highly marketable. Investing time into this certification offers a significant return by positioning you for high-level roles that dictate the technical direction of an organization.
Certified Site Reliability Manager Certification Overview
The program is delivered via the comprehensive curriculum found at the official course link and is hosted on the Sreschool platform. It utilizes a practical assessment approach that tests your ability to handle real-world scenarios rather than just multiple-choice questions. The certification levels take a candidate from foundational concepts to advanced organizational leadership. Because the program belongs to industry veterans, the structure remains relevant to the current needs of the global tech industry.
Certified Site Reliability Manager Certification Tracks & Levels
The certification is divided into foundation, professional, and advanced levels to cater to different stages of a career. Specialized tracks allow you to focus on specific domains such as DevOps integration, pure SRE management, or even financial operations for cloud resources. These levels align with typical career progression, moving from tactical implementation to strategic oversight. By following these tracks, a professional can build a specialized portfolio that demonstrates both breadth and depth in reliability management.
Complete Certified Site Reliability Manager Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundation | Junior Engineers | Basic Linux/Cloud | SLIs, SLOs, Error Budgets | 1 |
| Operations | Professional | Senior SREs | 3+ Years Experience | Incident Command, Postmortems | 2 |
| Management | Advanced | Lead Engineers | Professional Level | Capacity Planning, Team Lead | 3 |
| Specialized | Expert | Architects | Advanced Level | Chaos Engineering, AIOps | 4 |
Detailed Guide for Each Certified Site Reliability Manager Certification
Certified Site Reliability Manager – Foundation Level
What it is
This certification validates a professional’s understanding of the basic terminology and core philosophy behind site reliability engineering. It ensures that everyone on the team speaks the same language regarding service level objectives and system health.
Who should take it
This is suitable for junior developers, system administrators, or recent graduates who want to enter the world of production operations. It provides the necessary baseline for any cloud-based role.
Skills you’ll gain
- Defining SLIs and SLOs.
- Understanding the concept of “Error Budgets.”
- Basic automation and toil reduction strategies.
Real-world projects you should be able to do
- Create a basic monitoring dashboard for a web application.
- Draft a simple Service Level Agreement for an internal tool.
Preparation plan
- 7–14 days: Review core SRE whitepapers and definitions.
- 30 days: Complete the foundation labs on the hosting platform.
- 60 days: Not required for this level if the candidate has a tech background.
Common mistakes
- Overcomplicating the definition of service levels.
- Ignoring the cultural aspect of blameless postmortems.
Best next certification after this
- Same-track option: Professional SRE Manager.
- Cross-track option: DevOps Associate.
- Leadership option: Technical Team Lead Foundation.
Certified Site Reliability Manager – Professional Level
What it is
The professional level validates your ability to manage active incidents and implement complex reliability strategies across multiple services. It bridges the gap between individual task execution and team-wide operational excellence.
Who should take it
Senior engineers and current SREs with several years of experience should pursue this to prove they can handle high-pressure production environments.
Skills you’ll gain
- Advanced incident management and response.
- Implementing automated self-healing systems.
- Managing cross-team communication during outages.
Real-world projects you should be able to do
- Design an automated failover system for a multi-region deployment.
- Lead a complex post-incident review that results in architectural changes.
Preparation plan
- 7–14 days: Focused study on incident command structures.
- 30 days: Hands-on practice with simulation tools.
- 60 days: Deep dive into case studies of major industry outages.
Common mistakes
- Focusing too much on tools and not enough on processes.
- Failing to account for human factors during on-call rotations.
Best next certification after this
- Same-track option: Advanced Site Reliability Manager.
- Cross-track option: Cloud Security Professional.
- Leadership option: Engineering Manager Track.
Choose Your Learning Path
DevOps Path
The DevOps path focuses on the seamless integration of development and operations through continuous delivery. Since it emphasizes the entire lifecycle, it requires a strong grasp of CI/CD pipelines and infrastructure as code. Professionals here prioritize certifications that show how reliability is “baked in” during the build phase. This ensures that software stays healthy in production while developers deliver code quickly.
DevSecOps Path
In this path, engineers treat security as a fundamental component of reliability rather than an afterthought. Therefore, you must learn to automate security scans and compliance checks within the deployment process. It suits those who want to protect systems from vulnerabilities while maintaining high uptime. Reliability here means the system remains available and secure against evolving threats.
SRE Path
The pure SRE path serves those who live and breathe production excellence and system internals. Because this path is highly technical, it involves deep dives into kernel tuning, networking, and distributed systems. It focuses on the mathematical and engineering rigor required to maintain 99.99% availability. This represents the gold standard for those managing massive-scale cloud architectures.
AIOps Path
This track utilizes machine learning to automate the detection and resolution of IT issues. Because modern environments generate too much data for humans to track, AIOps professionals build intelligent alerting systems. They focus on noise reduction and predictive analytics to stop incidents before they happen. It attracts those interested in the intersection of data science and operations.
MLOps Path
MLOps professionals manage the unique reliability challenges of machine learning models in production. Since model drift and data quality can crash a system easily, this path focuses on specialized monitoring. You manage the lifecycle of models from training to deployment. This ensures that AI-driven features remain reliable and accurate for end users.
DataOps Path
DataOps focuses on the reliability and quality of data pipelines and large-scale data warehouses. Because businesses rely on real-time data for decision-making, the uptime of these pipelines remains critical. This path applies SRE principles like SLOs to data sets and transformation jobs. It is essential for engineers working in data-heavy industries like finance or healthcare.
FinOps Path
The FinOps path combines finance and engineering to ensure cloud spending stays efficient and reliable. Since a sudden spike in cloud costs can be as damaging as a technical outage, this role manages the “economic reliability” of a system. You learn to map cloud usage to business value and optimize resource allocation. Management values this path for its direct impact on the bottom line.
Role → Recommended Certified Site Reliability Manager Certifications
| Role | Recommended Certifications |
| DevOps Engineer | SRE Foundation, DevOps Professional |
| SRE | Professional SRE Manager, Chaos Engineering |
| Platform Engineer | Advanced SRE, Infrastructure as Code |
| Cloud Engineer | SRE Foundation, Cloud Architecture |
| Security Engineer | DevSecOps Specialist, Incident Response |
| Data Engineer | DataOps Professional, SRE Foundation |
| FinOps Practitioner | FinOps Certified, SRE Manager |
| Engineering Manager | Advanced SRE Manager, Leadership Track |
Next Certifications to Take After Certified Site Reliability Manager
Same Track Progression
Deep specialization involves moving toward expert-level certifications in niche areas like chaos engineering or advanced observability. By staying in this track, you become the primary authority on how systems behave under extreme stress. This path leads to roles such as Principal SRE or Distinguished Engineer. It is the best route for those who want to remain technical while increasing organizational influence.
Cross-Track Expansion
Skill broadening allows you to take your reliability knowledge and apply it to security or data domains. For example, moving from SRE to DevSecOps makes you a much more versatile asset to any high-tech firm. This expansion prevents silos and helps you understand the dependencies between different engineering departments. It serves those aiming for roles like Cloud Architect.
Leadership & Management Track
The transition to leadership involves moving from managing systems to managing the people who build them. Consequently, certifications in this track focus on strategic planning, budgeting, and organizational culture. You learn how to build high-performing teams that value reliability as a core business metric. This is the natural progression for those aiming for VP of Engineering or CTO positions.
Training & Certification Support Providers for Certified Site Reliability Manager
DevOpsSchool
DevOpsSchool provides a massive library of resources and live training sessions focused on end-to-end automation. They offer deep dives into various toolsets that complement reliability management perfectly for modern engineers.
Cotocus
Cotocus specializes in cloud-native technologies and provides hands-on labs that simulate real enterprise environments. Their trainers focus on practical implementation rather than just passing the exam.
Scmgalaxy
Scmgalaxy is an excellent resource for community-driven learning and technical documentation. They offer a wealth of blog posts and tutorials that help clarify complex SRE concepts for beginners and experts alike.
BestDevOps
BestDevOps focuses on delivering high-quality video content and structured courses for busy professionals. Their curriculum is designed to be consumed in bite-sized pieces without sacrificing technical depth.
devsecopsschool.com
devsecopsschool.com is the leading provider for security-focused operations training. They ensure that your reliability journey includes the necessary defensive strategies to keep production environments safe and compliant.
sreschool.com
sreschool.com provides the primary hosting and specialized content for site reliability management. Their platform is tailored specifically to the needs of the SRE community with updated labs and scenarios.
aiopsschool.com
aiopsschool.com offers specialized training in artificial intelligence for operations. They help engineers transition into the future of automated monitoring and intelligent incident response systems.
dataopsschool.com
dataopsschool.com focuses on the intersection of big data and reliable operations. Their courses are essential for anyone managing large-scale data pipelines and complex analytical environments.
finopsschool.com
finopsschool.com provides the necessary education for managing cloud economics. They help engineers understand the financial impact of their technical decisions and how to optimize for cost and performance.
Frequently Asked Questions
1. How difficult is it to get this certification?
The difficulty depends on your experience, but the professional level requires a strong grasp of production environments and management logic.
2. How much time does it take to prepare?
Most candidates find that 30 to 60 days of consistent study covers the technical and managerial aspects thoroughly.
3. Are there any prerequisites for the foundation level?
There are no strict prerequisites, but a basic understanding of Linux and cloud computing makes the learning process much smoother.
4. What is the return on investment for this program?
Professionals often see significant salary increases and more opportunities for senior leadership roles after obtaining this credential.
5. Can I skip levels if I have enough experience?
While skipping is possible, we recommend completing the foundation to ensure there are no gaps in your understanding of the core philosophy.
6. Is the exam based on specific tools?
No, the certification focuses on principles and processes that apply to any toolset, whether you use AWS, Azure, or Google Cloud.
7. How long is the certification valid?
The certification remains valid for two years, after which you may need to complete a refresher or advance to the next level.
8. Is this recognized globally?
Yes, the principles taught are based on industry standards used by major tech companies across the globe.
9. Does the program include hands-on labs?
Absolutely, the hosting platform provides interactive environments where you practice incident response and system configuration in real-time.
10. What if I fail the exam on the first try?
Most tracks offer a retake option, and the feedback provided identifies the specific areas where you need improvement.
11. How does this compare to a standard DevOps certification?
This specifically focuses on the management of reliability and uptime, whereas DevOps often focuses more on the delivery pipeline itself.
12. Are there group discounts for corporate teams?
Many providers offer corporate packages for engineering teams looking to standardize their reliability practices across the entire organization.
FAQs on Certified Site Reliability Manager
1. What makes a site reliability manager different from a traditional IT manager?
A site reliability manager uses an engineering approach to solve operational problems, focusing on automation and scalability rather than manual ticketing.
2. Do I need to be an expert coder for this role?
You must be comfortable reading code and writing scripts to automate repetitive operational tasks effectively, though you aren’t a senior developer.
3. How do I handle the cultural shift toward SRE in my company?
The certification teaches you how to implement blameless cultures and data-driven decision-making, which are essential for gaining buy-in from stakeholders.
4. What are the most important metrics for an SRE manager?
You focus on Service Level Objectives (SLOs), error budgets, and Mean Time to Recovery (MTTR) as your primary indicators of system health.
5. How does this role interact with the development team?
You act as a partner, helping them understand the production impact of their code while providing tools to maintain reliability.
6. Can I move into this role from a Quality Assurance background?
Yes, professionals in QA already have a mindset for system health and transition well by learning more about production operations.
7. Is this certification applicable to small startups?
The principles of reliability are universal, but the way you implement them scales according to the size and needs of your specific organization.
8. What is the primary goal of a Site Reliability Manager?
The primary goal is to create a sustainable balance between the need for rapid feature releases and the requirement for system stability.
Final Thoughts: Is Certified Site Reliability Manager Worth It?
Taking this step forward positions you perfectly for high-level technical management. Because the industry moves toward more complex, distributed systems, the need for leaders who understand reliability continues to skyrocket. This certification provides you with a structured framework to master these skills and proves to employers that you handle the responsibility of their most critical systems. Ultimately, it represents a practical investment in your future that moves you beyond being a tool user into a system leader. Embracing this role will clarify your career goals and provide the authority needed to drive meaningful change in any engineering organization.