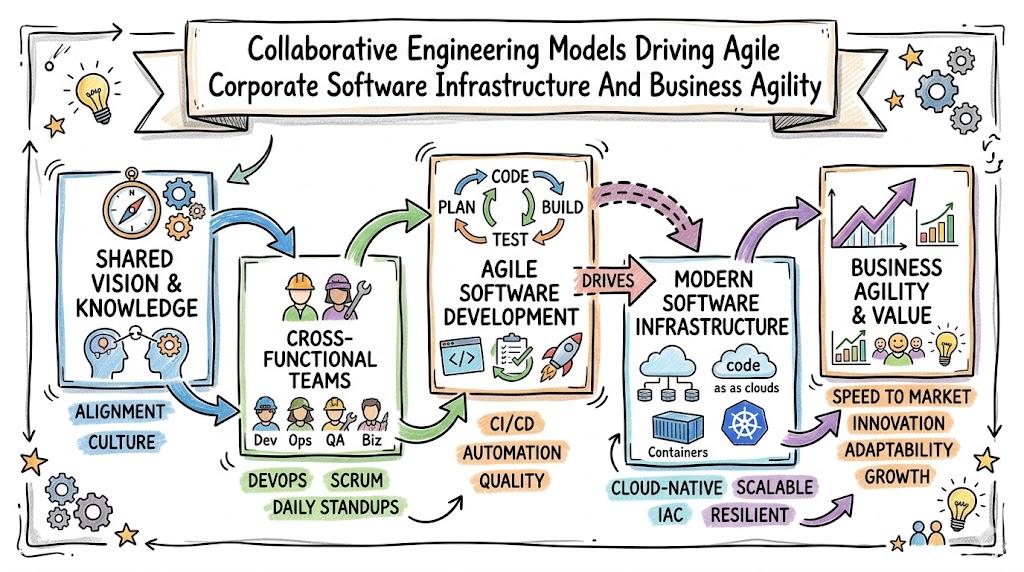
The Evolution of Modern Software Engineering Synergy
How DevOps Transforms Software Development and IT Operations represents the ultimate convergence of software engineering practices and automated information technology infrastructure management. This comprehensive methodology completely eliminates the historic boundaries separating software creators from system administrators, forging a unified operational ecosystem.
By integrating continuous delivery models, infrastructure automation, and real-time observability frameworks, organizations can accelerate feature delivery while maximizing platform resilience. This structural synchronization transforms raw application code into highly scalable, self-healing digital systems capable of adapting instantly to market demands.
Imagine a massive retail platform crashing right during the peak hours of a global holiday sale. The engineering team scrambles, but because the software developers do not understand the server configurations and the system administrators do not understand the code, everyone just points fingers while losses mount by the second. For years, traditional corporate environments suffered from this exact structural bottleneck, where disconnected departments threw unfinished applications over a metaphorical wall.
Fortunately, you can eliminate these painful operational friction points entirely. If you want to build resilient digital systems, discovering how to integrate your pipelines smoothly will completely revolutionize your software delivery velocity. You can easily elevate your production standards by exploring the modern learning paths available at Xopsschool, which bridges the gap between software development and stable infrastructure management.
This extensive guide provides a deep-dive roadmap into modern deployment practices, cultural transformations, and automated system infrastructure. You will learn the core architectural patterns that allow engineering teams to deploy code hundreds of times per day without sacrificing systemic safety. Furthermore, we will break down the essential metrics, reliability strategies, and platforms that top-tier technology enterprises use to maintain high availability at a global scale.
Deep Dive into DevOps Transformation
To truly grasp this operational shift, you must analyze how merging development and operations alters the entire lifecycle of software. This methodology is not just a collection of software applications, but rather a profound cultural and technical philosophy that unites previously isolated organizational components.
| Operational Pillar | Traditional Siloed Approach | Unified DevOps Approach |
| Deployment Frequency | Monthly or quarterly manual releases | Continuous, automated daily deployments |
| Risk Mitigation | Large, complex updates with high failure rates | Small, incremental changes with rapid rollbacks |
| Team Responsibility | Isolated ownership causing frequent friction | Shared accountability for code and uptime |
By implementing this unified approach, organizations eliminate long waiting periods, automate manual server setups, and establish automated testing mechanisms. Consequently, software developers gain a deep understanding of production environments, while system administrators actively participate in the early architecture design phase. This dual integration ensures that speed never compromises security or operational stability.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Historically, software creation followed rigid, linear pathways where developers focused exclusively on writing features. Once they completed the code, they handed it over to operations teams who had zero context regarding the application architecture.
Because these two departments operated under conflicting incentives, massive bottlenecks naturally emerged. Developers received praise for pushing new features quickly, whereas operations engineers received rewards for maintaining total system stability. Naturally, introducing new code introduces systemic instability, which created constant organizational friction and delayed critical software releases for months.
Moving Toward Unified Workflow Automation
As internet applications scaled rapidly, manual infrastructure configuration quickly became completely unsustainable for growing corporations. Teams realized that they needed a unified approach to automate repetitive workflows and standardize target environments.
Consequently, pioneering engineers began treating infrastructure configurations exactly like application source code, leading to the rise of automated workflow templates. This major transition allowed teams to spin up identical environments within minutes, which effectively eliminated the notorious mismatch problems between testing servers and live production systems.
Global Expansion Across Commercial Ecosystems
Once early tech enterprises demonstrated unprecedented deployment speeds, this collaborative framework spread rapidly across diverse commercial ecosystems worldwide. Traditional industries like banking, healthcare, and retail quickly recognized that slow software delivery cycles posed a direct threat to their market survival.
As a result, modern enterprises began restructuring their entire engineering divisions into cross-functional, autonomous units. This widespread structural evolution permanently shifted the technology market, making continuous delivery a baseline requirement for any organization aiming to scale its digital services efficiently.
Defining Strategic Operations Management
The Core Operational Structure
At its foundation, modern systems management relies on a continuous feedback loop that links planning, coding, building, testing, releasing, deploying, monitoring, and operating. This comprehensive lifecycle ensures that any issue occurring in production immediately informs the next development iteration.
Instead of treating software releases as disconnected, isolated events, the core architecture views software as a living, evolving organism. Therefore, information flows transparently across the entire pipeline, giving every engineer complete visibility into how code behaves under real-world user traffic.
+-------------------------------------------------------+
| Continuous Feedback Loop |
+-------------------------------------------------------+
| [Plan] -> [Code] -> [Build] -> [Test] -> [Release] |
| ^ | |
| | v |
| [Optimize] <- [Monitor] <- [Operate] <- [Deploy] |
+-------------------------------------------------------+
Daily Tasks of Systems Coordinators
Systems coordinators execute a wide variety of practical, highly technical tasks on a daily basis to keep platforms running smoothly. They spend significant portions of their day writing automated scripts to provision cloud instances, configure secure networks, and manage container deployments.
Additionally, these specialists continuously analyze live telemetry data, investigate sudden performance anomalies, and optimize resource allocation to reduce unnecessary infrastructure costs. They also collaborate directly with software engineering teams to ensure that new application features possess built-in logging and comprehensive health check endpoints.
Localized Control vs. Broad System Architecture
Managing a modern infrastructure requires a delicate balance between maintaining localized control and overseeing broad system architecture. Localized control involves tracking the specific performance metrics of individual application containers, local databases, or microservices.
Conversely, broad system architecture requires a high-level perspective to understand how hundreds of independent services interact with each other across global networks. Mastering this balance ensures that optimizing a single component does not inadvertently create an unexpected bottleneck or a cascading failure somewhere else in the wider network.
The Efficiency Mindset
Transitioning to this modern engineering model requires a profound cultural shift that prioritizes long-term system stability over short-term band-aid fixes. This efficiency mindset drives engineers to view every system failure as an invaluable opportunity to harden the architecture against future outages.
Instead of rushing to manually patch a broken server, specialists take the time to find the root cause, update the automation code, and redeploy the asset safely. This proactive behavior minimizes repetitive manual maintenance, allowing teams to dedicate their energy to building scalable, self-healing platforms.
The 7 Core Principles of Modern Operations
1. Embracing Risk and Managing Variability
Modern operations explicitly acknowledges that software systems are inherently complex and that achieving absolute 100% perfection is mathematically impossible. Therefore, instead of futilely striving for zero downtime, engineering teams calculate acceptable levels of systemic risk based on business realities.
By embracing this inevitable variability, organizations can confidently innovate and deploy new features without being paralyzed by the fear of minor, transient errors. The goal shifts from completely avoiding risk to managing it intelligently through robust architectural design.
2. Establishing Service Level Objectives (SLOs)
To manage operational risk effectively, you must establish clear, measurable targets for systemic success, commonly known as Service Level Objectives. These objectives serve as the definitive benchmark for determining whether an application is performing acceptably from the perspective of the end-user.
By defining precise targets for availability and speed, teams remove emotional opinions from engineering discussions. Consequently, these metrics provide an objective, data-driven framework that helps stakeholders balance feature development velocity with necessary platform stability investments.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, predictable, and manual operational work that lacks long-term strategic value and can be scaled linearly with system growth. Examples include manually resetting servers, creating user accounts one by one, or executing routine database cleanups by hand.
Modern engineering frameworks place a massive emphasis on identifying this repetitive work and systematically engineering it away through smart automation scripts. Eliminating this administrative burden frees up valuable engineering time, allowing specialists to focus on high-impact architectural improvements.
4. Monitoring & Observability Across the Pipeline
You cannot manage or improve what you cannot see, which makes comprehensive visibility across the entire operational environment absolutely vital. Modern observability goes far beyond basic uptime checks by collecting deep metrics, distributed traces, and detailed application logs from every layer of the infrastructure stack.
This deep visibility ensures that engineering teams can spot subtle performance degradations before they mutate into catastrophic outages. Furthermore, it allows engineers to map out complex data journeys across microservices, eliminating dangerous blind spots in distributed networks.
5. Automation Over Manual Coordination
Scaling modern digital workflows requires a strict engineering approach that favors software-driven automation over manual human coordination. Instead of relying on human operators to manually configure servers or execute deployment checklists, teams write declarative code to manage infrastructure.
This software-centric strategy ensures that every single operational change is entirely predictable, repeatable, and easily auditable. Consequently, code automation eliminates human error, accelerates delivery timelines, and allows a small engineering team to manage thousands of complex servers simultaneously.
6. Release Engineering and Deployment Stability
Release engineering is a dedicated discipline focused on building consistent, predictable, and safe strategies for delivering application updates to live users. This principle involves implementing sophisticated deployment patterns such as canary releases and blue-green deployments to minimize user impact during updates.
By testing new code variations on a tiny fraction of live traffic before a full-scale rollout, teams can easily identify bugs early. If an issue arises, automated rollback mechanisms instantly restore the previous stable version, ensuring maximum platform stability.
7. Simplicity in Network Architecture
As software systems expand, microservice environments can easily become incredibly convoluted, leading to hidden dependencies and complex failure modes. Therefore, modern operations champions extreme simplicity in network architecture, actively avoiding unnecessary layers, custom configurations, or esoteric software dependencies.
Keeping infrastructure minimal, standardized, and clean directly reduces the overall failure surface of your platform. Clean designs are vastly easier to document, troubleshoot, automate, and defend against security threats, which ultimately leads to a much more resilient corporate ecosystem.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the relationship between these three critical metrics is essential for managing system performance effectively. They form the foundational framework used to measure, discuss, and track platform reliability across the entire technology industry:
- SLA (Service Level Agreement): The overarching commitment made to external customers, defining the financial or legal penalties if service quality drops below a specific threshold.
- SLO (Service Level Objective): The internal target metric that your engineering team actively aims to hit, which is always set stricter than the formal SLA to provide a safe buffer.
- SLI (Service Level Indicator): The real-time, quantitative measurement of your system compliance, representing the actual percentage of successful requests at any given moment.
Error Budgets — The Game Changer for Operational Risk
An error budget is the exact mathematical inverse of your established Service Level Objective, representing the total allowable downtime your system can experience. For example, if your team commits to a 99.9% SLO, your system possesses a 0.1% error budget that you can safely expend during a specific window.
This metric completely transforms how organizations balance innovation with safety. As long as your error budget remains healthy and positive, developers can aggressively push new features and experimental code. However, if an unexpected series of outages completely depletes the error budget, feature releases instantly halt, and the entire team redirects its attention to platform stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as a silent productivity killer because it slowly drains engineering energy and stalls long-term platform evolution. To calculate and identify toil within your organization, you must look for tasks that are tactical, manual, repetitive, automatable, and devoid of permanent enduring value.
If your engineers spend more than 50% of their time performing routine operational maintenance, your infrastructure is accumulating massive operational debt. Systematically eliminating this burden requires teams to write automated software tools that handle these mundane tasks self-sufficiently without human intervention.
Incident Management & Postmortems
When unexpected production outages occur, modern organizations activate structured incident management procedures to restore service as quickly as humanly possible. Once the system returns to a stable state, the team conducts a comprehensive, completely blameless postmortem meeting to analyze the failure events.
A blameless culture assumes that engineers always act with good intentions based on the information they possess at the time. Therefore, instead of assigning individual blame, the team looks for systemic architectural flaws, inadequate tooling, or gaps in monitoring that allowed the failure to occur.
Capacity Planning
Capacity planning involves forecasting future user demand, organic business growth, and application traffic spikes to prepare underlying hardware infrastructure well in advance. Without accurate capacity forecasting, systems run the risk of sudden saturation, causing severe performance degradation or total platform collapse during major traffic events.
Engineers use historical trend data, seasonal traffic patterns, and simulated load testing to determine exactly when they must scale out their compute resources. This predictive methodology ensures that the organization avoids both expensive over-provisioning and dangerous resource starvation.
The Four Golden Signals of Pipeline Performance
If you want to maintain complete visibility over your distributed systems, you must focus your monitoring efforts around the four golden signals of performance:
- Latency: The precise time it takes to successfully process a specific request, making sure to differentiate between successful and failed requests.
- Traffic: The overall demand being placed on your system, measured via metrics like HTTP requests per second or network bandwidth consumption.
- Errors: The rate of requests that fail explicitly, return internal server errors, or violate predefined business logic policies.
- Saturation: A measure of how close your infrastructure resources are to reaching their maximum capacity limits, such as memory or CPU usage.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many professionals mistakenly confuse cultural engineering philosophies with specific platform implementations, but they represent entirely distinct concepts. The cultural approach focuses heavily on broad organizational mindsets, human communication, empathy, breaking down historical silos, and sharing equal responsibility across teams.
On the flip side, platform implementation focuses squarely on the concrete engineering methodologies, software tools, and specific code patterns used to achieve high reliability. While the culture defines the underlying values, the implementation provides the tactical execution model required to realize those values in production.
Roles & Responsibilities Compared
To understand how these concepts differentiate in day-to-day operations, examine the specific focuses of each approach:
- Cultural Focus:
- Fostering open communication channels between diverse development and operations teams.
- Encouraging shared organizational accountability for both product innovation and system uptime.
- Promoting a psychologically safe environment through blameless incident reviews.
- Focusing on business agility, team alignment, and rapid customer feedback loop integration.
- Implementation Focus:
- Writing clean declarative code to automatically provision cloud environments and networks.
- Building robust CI/CD automation pipelines to compile, test, and package applications.
- Configuring complex observability backends, log aggregators, and real-time alerting systems.
- Developing custom software tools to automate away manual infrastructure tasks and toil.
Can You Have Both Disciplines?
You absolutely can—and should—embrace both disciplines simultaneously within a modern, forward-thinking technology organization. In fact, they are deeply complementary frameworks that achieve maximum effectiveness when deployed together across an enterprise.
The cultural philosophy provides the collaborative foundation and open communication patterns that allow technical implementation teams to build relevant automation tools. Without the cultural alignment, technical tools often fail to gain adoption; without technical tools, cultural ideals remain theoretical concepts without practical impact.
Which One Should Your Team Adopt?
Choosing which approach to prioritize depends heavily on your organizational size, current engineering maturity, and pressing operational pain points. If your main problems stem from interpersonal friction, finger-pointing, and disjointed team priorities, you must focus heavily on fixing your engineering culture first.
However, if your developers already communicate brilliantly but your live production environments suffer from frequent manual configuration errors, you need a technical implementation overhaul. Use the clear, structured decision framework below to evaluate your organizational trajectory.
| Current Organization State | Primary Operational Problem | Recommended Priority Focus |
| Fragmented teams, high blame culture | Heavy finger-pointing during major outages | Cultural Alignment & Blameless Reviews |
| Collaborative teams, manual setups | Frequent human errors during server configuration | Technical Infrastructure Automation |
| Rapidly growing startup scaling fast | Unpredictable deployments and lack of visibility | Full CI/CD & Observability Implementation |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global technology leaders rely intensely on real-time data tracking practices to manage their sprawling, multi-region cloud infrastructures. These enterprises do not guess system health; they track billions of metrics every second using highly sophisticated dashboard networks.
By analyzing long-term historical performance trends, these organizations can instantly detect microscopic variations in latency or error rates that signify a larger underlying problem. This data-driven approach allows tech giants to isolate buggy code variations instantly, protecting the vast majority of their global user base from disruptions.
Chaos Engineering Approaches to Resilient Systems
To guarantee absolute reliability, advanced engineering teams do not sit around waiting for natural infrastructure failures to happen. Instead, they practice chaos engineering, which involves intentionally injecting controlled faults directly into live production environments.
For instance, automated software scripts might randomly terminate server instances, inject network latency, or simulate datacenter power outages during standard working hours. This proactive disruption forces the engineering architecture to prove its self-healing capabilities, uncovering hidden vulnerabilities before they cause an actual emergency.
Handling Reliability at Massive Scale
Distributed microservices architectures handle hundreds of millions of transactions safely by utilizing decoupled design patterns that isolate failures. When an individual service experiences heavy traffic saturation or an unexpected crash, modern architectures prevent that failure from cascading across the entire application.
Teams implement sophisticated circuit breakers, rate limiters, and intelligent retry queues to gracefully degrade non-essential application features while keeping core transactional systems operational. This architectural resilience ensures that a minor failure in a minor sub-system never compromises the entire enterprise platform.
High-Availability in Fintech Operations
Financial technology platforms operate under zero-tolerance rules for system downtime, as even a few seconds of interruption can cause massive financial losses. Therefore, fintech operations utilize active-active multi-region deployment configurations, where customer financial transactions are simultaneously processed across independent geographic locations.
If an entire cloud region suffers a major catastrophic outage, automated DNS routing mechanisms instantly shift all user traffic to surviving datacenters. This continuous, ultra-redundant architecture ensures that transactional systems maintain perfect availability and data consistency without dropping a single payment.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not possess the massive engineering budgets of large enterprises, but they still apply these core operational principles efficiently. By utilizing managed cloud solutions and serverless architectures, small teams can easily automate their entire deployment pipeline without massive overhead.
Startups focus their limited energy on setting up basic, foundational CI/CD pipelines and essential uptime alerts right from day one. This investment in automation ensures that as the startup scales its user base, its core software infrastructure remains completely stable and manageable.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A devastating misconception in technology is viewing operations as merely a modern, renamed version of traditional on-call technical support. If your engineering team spends their entire day frantically responding to pages and manually fixing broken production servers, they are trapped in a reactive loop.
True modern systems management is an active engineering discipline where specialists write software to build long-term, self-healing platforms. If your team does not have dedicated time to write automation code that permanently fixes the root causes of alerts, your infrastructure will eventually collapse under operational weight.
Mistake 2 — Setting Unrealistic SLOs
Many ambitious organizations fall into the dangerous trap of demanding perfect 100% availability for their applications without calculating the actual financial costs. Striving for unrealistic uptimes requires immense infrastructure redundancy, complex engineering architectures, and massive financial investments that rarely align with actual business value.
Furthermore, demanding extreme availability completely stalls your feature release velocity because developers must expend their entire error budget on maintaining baseline safety. Smart teams recognize that an objective, slightly lower uptime target is far healthier for both product innovation and developer sanity.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring manual toil is a critical mistake that accumulates massive operational debt over time, eventually grinding engineering velocity to a halt. When minor manual tasks are ignored, they compound exponentially as your user traffic and infrastructure footprint grow.
Eventually, your highly skilled engineers will spend all their working hours performing repetitive administrative maintenance instead of building innovative platform features. This lack of strategic engineering creates a miserable work environment, slows down product evolution, and leads to massive burnout across your technical staff.
Mistake 4 — Skipping Blameless Postmortems
When an organization embraces a toxic culture of blame, engineers naturally hide their mistakes, delay incident notifications, and cover up architectural vulnerabilities out of fear. Skipping blameless reviews ensures that your team will never uncover the true systemic deficiencies that caused an outage in the first place.
Without open, honest communication regarding what went wrong, the exact same failure patterns will inevitably repeat themselves over and over again. Cultivating a safe, transparent postmortem environment is the only way to convert operational failures into powerful lessons that harden your systems.
Mistake 5 — Monitoring Without Actionable Alerts
Many teams build overly complex monitoring dashboards that generate thousands of daily alerts for minor, non-critical fluctuations in system metrics. This excessive noise creates severe alert fatigue, causing exhausted engineers to ignore notifications or miss critical warnings during a genuine system emergency.
Every single alert that pages an on-call engineer must be actionable, clear, and demand an immediate human response to prevent actual user degradation. If a notification does not require immediate intervention, it should be routed to a quiet email log rather than waking up an engineer.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Waiting until an application is completely coded before involving your operations team is a recipe for catastrophic production failures. Software developers often design complex features without understanding the real-world constraints of the network infrastructure, leading to severe scaling bottlenecks later on.
Operational specialists must be integrated into the initial architectural design conversations right from day one. This early collaboration ensures that applications are built from the ground up to be observable, secure, horizontally scalable, and highly resilient in production.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete, granular visibility over complex distributed systems requires a robust collection of enterprise monitoring and observability platforms. Specialists use tools like Prometheus to scrape high-fidelity time-series metrics and Grafana to build beautiful, real-time visualization dashboards.
Additionally, tools like Datadog and New Relic provide deep, end-to-end application performance monitoring by automatically tracing requests across complex microservices. These observability suites ensure that teams can spot performance regressions, analyze dependency bottlenecks, and troubleshoot production issues before users ever complain.
Incident Management
When major production outages inevitably strike, organizations use dedicated incident response platforms to orchestrate their technical teams effectively. PagerDuty acts as the critical routing engine that automatically alerts the correct on-call engineers based on live telemetry data.
These incident management platforms integrate directly with corporate communication tools to create centralized war rooms, document incident timelines, and manage escalation paths automatically. This structured coordination minimizes chaos during high-stress scenarios, helping teams restore vital digital services with maximum efficiency.
CI/CD & Release Engineering
Automating the movement of code from a developer’s laptop to a live production server requires powerful continuous integration and delivery engines. Jenkins serves as a highly customizable automation workhorse for compiling applications and executing complex test suites.
For modern containerized environments, teams rely heavily on GitOps controllers like Argo CD and advanced continuous delivery engines like Spinnaker. These platforms ensure that your live infrastructure state perfectly mirrors the declarative configurations stored securely within your version control repositories.
Chaos Engineering
Building truly resilient platforms requires software tools explicitly designed to safely inject controlled failures directly into live engineering environments. Chaos Monkey, originally pioneered by tech industry giants, automatically terminates random server instances within production networks to test system adaptability.
Using these controlled failure injection tools allows teams to verify that their automated failover mechanisms and redundancy architectures perform exactly as designed. This proactive verification process turns hypothetical platform resilience into proven, verifiable operational reality.
SLO Management
As data-driven reliability practices expand, modern engineering teams utilize dedicated platforms to track their performance compliance metrics in real time. Nobl9 allows organizations to ingest metric streams from multiple monitoring sources and calculate precise error budget consumption rates.
These specialized tools provide business stakeholders and technical leads with clear, automated alerts when an error budget degrades too quickly. Consequently, having this early warning system allows teams to make proactive adjustments to their deployment velocity before violating key customer agreements.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Breaking into this elite engineering field requires a strong foundational mastery of command-line interfaces, systems programming, and modern cloud architecture concepts. You must become deeply comfortable navigating the Linux terminal, managing filesystems, and writing automation scripts using languages like Python or Go.
Additionally, you need to understand core networking concepts like TCP/IP, DNS routing, load balancing configurations, and secure SSH communication. Mastering these foundational infrastructure elements is absolutely essential before you attempt to manage large-scale distributed cloud systems.
+-------------------------------------------------------+
| Foundational Skills Roadmap |
+-------------------------------------------------------+
| [Linux Terminal] -> [Scripting: Python/Go] |
| | |
| v |
| [Networking: TCP/IP/DNS] -> [Cloud Architecture] |
+-------------------------------------------------------+
The Professional Learning Path
The journey to senior infrastructure expertise follows a clear, step-by-step educational progression that expands your architectural responsibilities over time. You start by learning how to configure single virtual servers and deploy basic web applications manually.
Next, you transition to containerization tools like Docker and container orchestration platforms like Kubernetes to manage fleet deployments. Finally, you master infrastructure as code frameworks, distributed system observability, and high-availability architecture design to lead enterprise-level digital transformations.
Certifications Worth Pursuing
Industry-recognized credentials serve as an excellent way to validate your technical infrastructure expertise and accelerate your career growth. Pursuing certifications like the Certified Kubernetes Administrator (CKA) demonstrates your deep technical capability to manage complex containerized workloads at scale.
Additionally, obtaining advanced cloud architecture credentials from major public cloud vendors showcases your comprehensive understanding of modern cloud ecosystems. These rigorous certifications signal your strong dedication to potential employers and prove you possess the practical skills required to defend complex enterprise platforms.
Educational Resources with Xopsschool
If you want to accelerate your engineering journey, exploring the professional curricula offered by Xopsschool is a phenomenal move. They provide comprehensive, hands-on training courses designed explicitly to mirror the fast-paced realities of the modern tech sector.
By working through real-world simulation projects, you will learn exactly how to configure automation pipelines, manage microservices, and troubleshoot live production failures. This practical, mentor-guided education bridges the gap between theoretical knowledge and senior-level architectural execution.
The Future of Systems Management
AI and Automation in System Optimization
The next major frontier in systems management involves integrating advanced machine learning algorithms directly into the core observability stack. AI-driven operations platforms can analyze petabytes of historical telemetry data to identify incredibly subtle anomaly patterns that human engineers could never spot.
These intelligent systems can automatically forecast resource saturation, detect security anomalies, and accelerate root cause analysis during complex outages. Over time, these platforms will transition from basic anomaly detection to executing automated, self-healing remediation scripts completely independently.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly emerging as the natural evolution of infrastructure management, focusing heavily on improving the overall developer experience. Instead of requiring every software developer to become an expert in complex cloud networks, platform teams build Internal Developer Platforms (IDPs).
These secure, self-service portals allow developers to independently spin up databases, provision infrastructure, and deploy applications using pre-approved, automated templates. This brilliant abstraction eliminates internal organizational friction, protects infrastructure security, and drastically accelerates feature delivery timelines.
Management in Cloud-Native & Kubernetes Environments
As enterprises migrate fully to cloud-native ecosystems, managing dynamic containerized clusters presents unique orchestration and scaling challenges. Kubernetes has firmly established itself as the operating system of the modern cloud, demanding deep expertise in distributed state management.
Future infrastructure experts must move beyond basic cluster configurations and master advanced concepts like service meshes, multi-cluster networking, and edge computing. Navigating these highly volatile environments requires a profound understanding of dynamic resource scheduling and automated network security policies.
Operational Skills That Will Matter Most
Looking ahead, the most successful infrastructure specialists will be those who balance deep technical expertise with strong business acumen. FinOps, which involves optimizing cloud architecture configurations to maximize financial efficiency, is becoming a critical priority for modern enterprises.
Additionally, mastering advanced data observability and building psychological safety within engineering teams will remain incredibly vital. The future belongs to adaptive professionals who can effortlessly connect technical automation pipelines directly with overarching corporate business strategies.
FAQ Section
- What is the standard career path for an aspiring infrastructure specialist?Most professionals begin their career journey as junior systems administrators or software engineers, focusing on basic script automation and server maintenance. Over time, they master container orchestration, cloud architecture design, and advanced observability pipelines, eventually advancing into senior platform architect roles.
- How does this modern engineering methodology define the role of a system coordinator?A system coordinator acts as the essential bridge that unifies software development priorities with live production environment stability requirements. They spend their days writing declarative infrastructure code, optimizing automated deployment pipelines, and building robust monitoring systems to guarantee high platform availability.
- What are the prevailing salary trends for professionals in this technical domain?Due to the critical shortage of specialized engineering talent, certified infrastructure experts command some of the highest salaries in the technology market. Senior engineers and platform architects frequently outpace traditional software developers in total compensation, reflecting their immense structural value to modern corporations.
- Why is an error budget considered a game changer for operational risk management?An error budget removes emotional arguments from engineering conversations by providing a clear, mathematical framework that balances product innovation speed with system safety. It allows developers to deploy code aggressively when the budget is healthy, but automatically shifts team focus to stability if outages deplete the buffer.
- Can small startups implement these comprehensive architectural principles without a massive budget?Startups can easily implement these core methodologies by leveraging managed public cloud services and serverless computing models to minimize operational overhead. Focusing on basic automated testing and essential uptime alerts early on allows small teams to scale their code securely without incurring massive infrastructure costs.
- What is the core difference between monitoring a system and achieving true observability?Monitoring simply alerts your engineering team when a specific system component fails or crosses a predefined threshold, telling you what is broken. Observability uses rich logs, metrics, and distributed traces to allow you to infer the internal state of a complex system, explaining why it failed.
Final Summary
Maintaining exceptional system health across complex corporate environments requires a profound, permanent commitment to blending collaborative culture with advanced software automation. By embracing structured reliability frameworks, tracking performance metrics diligently, and eliminating manual toil, modern organizations can confidently scale their digital platforms without experiencing catastrophic disruptions. Ultimately, the future of enterprise software delivery belongs to cross-functional teams that treat infrastructure configuration with the exact same engineering discipline as application source code. Elevating your operational standards requires continuous education, and you can easily unlock these advanced technical capabilities by partnering with Xopsschool to master the modern landscape of high-availability engineering.