Imagine waking up at two in the morning to a catastrophic system outage that wipes out half of your active digital transactions, costing your enterprise thousands of dollars every single minute. Traditional operations teams typically scramble blindly through fragmented server logs while frantic business executives demand instant answers during these high-pressure system disruptions. Fortunately, modern technology teams can successfully eliminate this chaotic reactive loop by embracing comprehensive operational methodologies that unify disparate engineering disciplines. This complete guide uncovers how integrating cross-functional operational practices systematically optimizes infrastructure performance, boosts workflow velocity, and drastically reduces wasteful cloud spending across your entire organization. You can discover the ultimate roadmap to mastering these modern strategies by exploring the advanced professional programs at Xopsschool, where you will build the precise engineering skills required to orchestrate resilient, cost-effective digital platforms at scale.
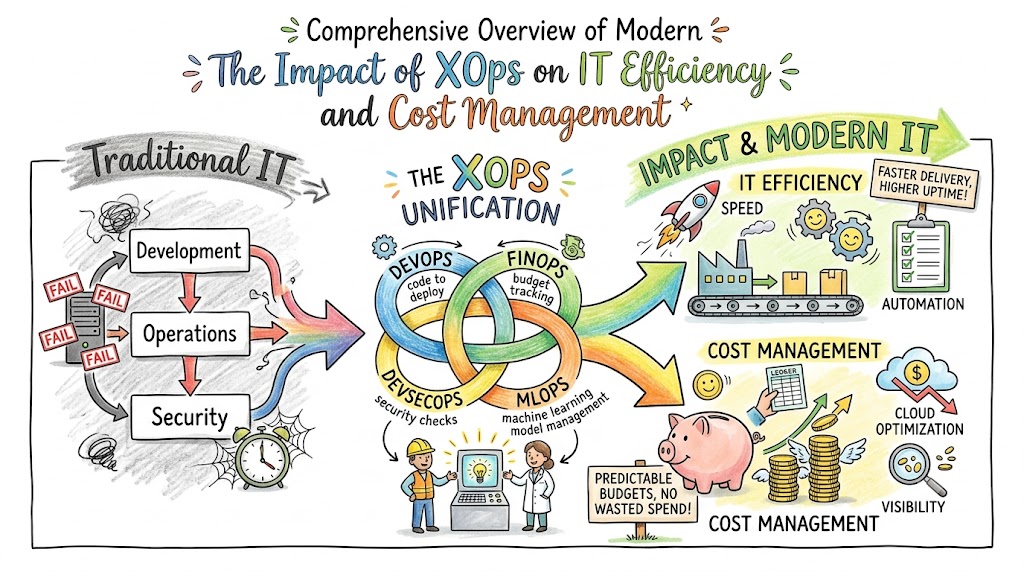
Detailed Breakdown of XOps Methodologies
To fully comprehend the deep commercial implications of these strategies, we must first analyze what XOps actually represents within the modern corporate ecosystem. Essentially, XOps is an umbrella framework that synthesizes various specialized operational disciplines—including DevOps, DevSecOps, MLOps, FinOps, and GitOps—into a singular, highly automated, and collaborative organizational culture. Rather than allowing individual technology teams to work in isolated silos, this unified framework establishes automated continuous integration and continuous deployment pipelines, structural security guardrails, data science workflows, and real-time financial tracking directly into the core software development lifecycle. Consequently, organizations can seamlessly scale their cloud environments without experiencing exponential spikes in manual management overhead or running into massive architectural bottlenecks.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
For many decades, traditional software development environments suffered from a deep systemic division between the creative development teams and the localized operations staff. Developers focused almost exclusively on writing code and pushing out innovative new features as quickly as possible to satisfy business requirements. Meanwhile, operations teams carried the heavy burden of maintaining production system stability, which naturally made them highly resistant to frequent software modifications.
Because these two departments operated with completely conflicting goals, software releases required weeks of manual validation, stressful handoffs, and tedious cross-departmental paperwork. This fragmented approach inevitably triggered frequent production crashes, extended system downtime, and severe communication breakdowns whenever critical infrastructure issues emerged.
Moving Toward Unified Workflow Automation
As internet adoption exploded globally, forward-thinking organizations quickly realized that this rigid division of labor was entirely unsustainable for rapid digital innovation. Engineering leaders began breaking down these historical communication walls by introducing automated shared pipelines that naturally unified code creation with infrastructure deployment.
+-------------------+ Unified CI/CD Pipeline +---------------------+
| Development Team | =============================> | Operations Team |
| (Writes Software) | [Automated Testing & Build] | (Maintains Systems) |
+-------------------+ +---------------------+
By utilizing early configuration management scripts, teams successfully replaced error-prone manual server setups with predictable, repeatable code blocks. This monumental shift effectively aligned developer velocity with infrastructure reliability, giving birth to a highly collaborative automation culture that transformed how modern software reaches production.
Global Expansion Across Commercial Ecosystems
Subsequently, these foundational automated workflows expanded rapidly beyond simple web companies to capture major global commercial enterprises, including legacy banks, massive retail networks, and healthcare systems. Organizations discovered that automating application delivery allowed them to respond instantly to shifting market demands while maintaining rock-solid system integrity.
As corporate IT environments evolved from basic physical servers into highly complex multi-cloud architectures, unified operational strategies became an absolute baseline necessity for global business survival. Today, these frameworks serve as the standard operational blueprint for any large-scale tech enterprise aiming to dominate its respective digital market.
Defining Strategic Operations Management
The Core Operational Structure
The underlying structural architecture of modern system coordination relies entirely on an ongoing, data-driven feedback loop that connects software code directly to live production environments. Engineers treat infrastructure exactly like application software, utilizing declarative configuration files that sit safely inside centralized version control repositories.
Whenever an engineer modifies a configuration file, automated deployment engines instantly validate the change, run rigorous automated tests, and precisely apply the update across target servers. This structured layout ensures that the entire state of your global infrastructure remains fully visible, completely auditable, and entirely trackable over time.
Daily Tasks of Systems Coordinators
On any given day, an infrastructure specialist executes a diverse blend of software development, system monitoring, and preventative maintenance tasks. These technical professionals spend significant portions of their morning writing reusable automation scripts to provision cloud resources and eliminate tedious manual tasks.
[Morning: Scripting & Automation] --> [Midday: Monitor Performance & Traffic] --> [Afternoon: Architecture Design]
During the midday hours, they closely analyze performance dashboards, fine-tune alert thresholds, and proactively adjust cloud resource allocations to handle incoming user traffic spikes. Furthermore, they partner closely with software development squads to architect highly resilient application paths that avoid single points of technical failure.
Localized Control vs. Broad System Architecture
To build a highly efficient technology department, leadership must maintain a healthy balance between localized component control and broad systemic infrastructure engineering. Localized control concentrates deeply on optimizing specific software instances, single database nodes, or individual microservices to ensure they run as quickly as possible.
Conversely, broad system architecture takes a holistic view of the entire global network, orchestrating how hundreds of interconnected services communicate safely across multiple regions. Successful organizations understand that micro-level optimizations remain completely useless if the macro-level system architecture suffers from fundamental structural bottlenecks.
The Efficiency Mindset
Transitioning to a modern operational framework requires a profound cultural transformation that places long-term system stability and financial efficiency at the center of every engineering decision. Teams abandon the old, reckless habit of deploying broken software quickly and dealing with the messy fallout later.
Instead, every single engineer adopts a proactive mindset focused on building highly observable, self-healing systems that automatically detect and remediate internal errors. This long-term cultural shift helps technology organizations move away from stressful fire-fighting emergencies and transition into a peaceful state of continuous, predictable optimization.
The 7 Core Principles of XOps
1. Embracing Risk and Managing Variability
Modern engineering teams completely accept the hard reality that physical hardware components will eventually fail, software bugs will slip through, and cloud networks will occasionally drop packets. Because achieving perfect 100% system uptime remains mathematically impossible and financially ruinous, engineers focus on defining and managing acceptable levels of operational risk.
By calculating the precise amount of service disruption that end-users can tolerate before becoming genuinely dissatisfied, teams can intelligently balance innovation velocity with baseline stability. This realistic approach ensures that you never waste valuable engineering hours chasing unnecessary, overly restrictive reliability targets.
2. Establishing Service Level Objectives (SLOs)
A highly successful operation relies heavily on converting ambiguous business goals into clear, quantifiable data targets that guide daily engineering priorities. Teams meticulously establish specific Service Level Objectives that act as the definitive target metrics for system health, user satisfaction, and structural performance.
These objective performance targets eliminate emotional debates between aggressive product managers demanding rapid feature updates and conservative operations engineers wanting to lock down production. As long as system metrics remain safely within these defined targets, development teams retain complete freedom to deploy innovative features.
3. Eliminating Toil and Manual Processes
Toil represents any repetitive, mundane, and manual operational task that directly scales with the overall size of a production system but adds no permanent structural value. Examples include manually resetting stuck application servers, manually copying database files, or executing repetitive checklist procedures during software updates.
Modern operational frameworks prioritize identifying this manual workload and tasking engineers with writing smart software code to automate these tasks out of existence. Eliminating this heavy cognitive burden frees up your technical talent to design creative, long-term architectural improvements instead of performing boring chores.
4. Monitoring & Observability Across the Pipeline
Comprehensive system visibility requires moving far beyond basic infrastructure monitoring dashboards that merely show whether a particular server is currently online or offline. Advanced observability empowers engineering teams to gather rich telemetry data—including detailed event logs, distributed request traces, and precise system metrics—across the entire pipeline.
Telemetry Inputs Data Observability Engine Engineering Outcome
+-----------------------+ +--------------------------+ +---------------------------+
| Logs + Metrics + Traces | --> | Real-time Stream Analysis | --> | Actionable System Insights |
+-----------------------+ +--------------------------+ +---------------------------+
This deep multi-layered visibility allows engineers to trace complex user transactions as they journey through intricate microservice layers and back-end database tables. Consequently, when an unexpected performance drop occurs, teams can pinpoint the exact root cause in seconds rather than blindly guessing for hours.
5. Automation Over Manual Coordination
Scaling modern, global enterprise infrastructure simply cannot be achieved through manual human coordination, multi-page instruction documents, or complex operational spreadsheets. Instead, engineering organizations leverage intelligent software solutions to automatically deploy, scale, and repair complex infrastructure environments based on real-time traffic demands.
Automated systems can effortlessly provision thousands of clean virtual servers, adjust complex network routing tables, and roll back broken software updates without human intervention. This heavy reliance on programmatic automation ensures that your infrastructure operations remain highly consistent, completely error-free, and instantly scalable.
6. Release Engineering and Deployment Stability
High-quality release engineering treats the entire software deployment process as an exact, repeatable, and highly disciplined science rather than an unpredictable artistic endeavor. Teams build highly sophisticated continuous integration and continuous deployment pipelines that subject every code change to rigorous automated security scans and quality tests.
By adopting advanced deployment strategies like canary releases or blue-green environments, teams can safely expose new features to a tiny fraction of live users first. This defensive approach allows you to verify code performance in real production environments while containing potential software bugs safely away from the general public.
7. Simplicity in Network Architecture
Extremely complex network designs and convoluted software architectures represent some of the most dangerous hidden threats to enterprise system reliability and financial cost control. When an environment features too many overlapping components, custom configurations, and fragile dependencies, identifying the cause of an outage becomes incredibly difficult.
Modern operational principles explicitly dictate that infrastructure must remain as clean, minimal, and uniform as humanly possible. By purposely reducing the overall structural attack surface and removing redundant software layers, organizations can minimize unexpected system behaviors and build highly predictable environments.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Navigating modern enterprise operations requires a crystal-clear understanding of the foundational data indicators that define system success. The table below outlines the core differences between these three essential operational metrics:
| Metric Type | Core Definition | Primary Target Audience | Business or Technical Purpose |
| SLA (Service Level Agreement) | The formal legal contract specifying system commitments | External clients, business executives, legal teams | Outlines financial or legal penalties if system availability drops below a specific mark. |
| SLO (Service Level Objective) | The internal target metric defining system reliability | Product managers, development teams, site engineers | Directs daily engineering priorities and balances release velocity with baseline stability. |
| SLI (Service Level Indicator) | The real-time metric measuring current system performance | Systems coordinators, monitoring tools, automation scripts | Computes the exact percentage of successful requests at any given moment in time. |
Error Budgets — The Game Changer for Operational Risk
The error budget represents the exact mathematical inverse of your internal Service Level Objective metric over a specific multi-week window. For instance, if your engineering team establishes an SLO of 99% uptime for a critical microservice, you possess a 1% error budget for permissible downtime.
This mathematical budget acts as a dynamic currency that developers can actively spend on pushing risky updates or running experiential architectural tests. However, if a series of production outages completely drains this error budget, feature deployments instantly pause, and resources pivot to stability engineering.
Toil — The Silent Productivity Killer in Infrastructure
Toil slowly drains organizational energy, crushes technical innovation, and triggers widespread burnout across your most talented systems engineering staff. To successfully calculate and permanently eliminate this administrative drain, teams can follow this clear four-step remediation framework:
- Audit Every Process: Document all manual actions taken by on-call engineers over a two-week period.
- Categorize by Type: Isolate tasks that are repetitive, tactical, and lack long-term creative value.
- Quantify Human Hours: Calculate the exact total time wasted on these manual chores each month.
- Build Automation Software: Assign a dedicated engineering sprint to write robust code that solves the issue permanently.
Incident Management & Postmortems
Whenever an unexpected production incident occurs, high-performing organizations launch a highly structured, blameless incident response protocol designed to restore service rapidly. Once the immediate fire is extinguished, engineers come together to write an incredibly detailed postmortem document that explores structural flaws.
A truly blameless culture assumes that every engineer acted with good intentions based on the specific information they possessed at that moment. Rather than pointing fingers at individuals, the investigation focuses deeply on fixing the underlying systemic weaknesses that permitted the human mistake to happen.
Capacity Planning
Predictive capacity planning enables modern digital enterprises to maintain high performance while preventing wasteful over-provisioning of cloud resources. Instead of buying expensive hardware based on vague intuition, engineers analyze historical traffic trends, organic business growth data, and seasonal marketing patterns.
By feeding this rich data into predictive mathematical models, teams can accurately forecast exactly when their existing database clusters will run out of space. This foresight allows organizations to scale up infrastructure safely ahead of major demand spikes, protecting user experience while keeping budgets completely lean.
The Four Golden Signals of Pipeline Performance
To understand exactly how well your internal infrastructure pipeline is handling user demands, teams must trace the four golden performance signals:
- Latency: The precise time it takes for a system to complete a user request successfully.
- Traffic: A direct measure of total system demand, such as HTTP requests per second.
- Errors: The total rate of incoming user requests that fail to process correctly.
- Saturation: A metric tracking how close a system resource is to reaching its maximum limits.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many corporate technology leaders mistakenly assume that simply purchasing expensive software licenses instantly transforms their business into a modern operational powerhouse. In reality, platform implementation focuses purely on installing modern tools, setting up cloud infrastructure, and configuring automated software delivery pipelines.
Conversely, the deeper cultural philosophy represents how human beings communicate, share operational responsibilities, and view systemic mistakes within the everyday workplace. Installing advanced automated platforms remains largely ineffective if your underlying corporate culture continues to punish engineers for talking openly about production failures.
Roles & Responsibilities Compared
To clarify how these operational ideas impact human structures, the table below highlights the distinct day-to-day focuses within a modern enterprise:
| Focus Area | Cultural Transformation Teams | Platform Engineering Teams |
| Primary Mission | Breaking down historical silos and improving shared communication | Building scalable internal tools and managing automated pipelines |
| Core Daily Deliverables | Blameless postmortem reviews, aligned business goals, shared workflows | Golden paths, cloud orchestration, internal developer portals |
| Primary Metric of Success | Cross-departmental deployment speed and team collaboration rates | Total tool adoption, infrastructure cost savings, developer velocity |
Can You Have Both Disciplines?
Modern, highly successful technology companies do not treat cultural alignment and technical platform engineering as mutually exclusive organizational choices. Instead, they run these two crucial engineering movements simultaneously, allowing them to feed off and strengthen each other across departments.
A healthy, supportive engineering culture naturally helps identify exactly what types of internal software platforms developers need to move faster safely. At the same time, a well-built automated platform makes it incredibly easy for engineers to practice healthy operational habits without extra friction.
Which One Should Your Team Adopt?
Deciding where to invest your primary engineering energy depends heavily on your current organization size and overall technical maturity levels. Small, early-stage startups should focus intensively on building a collaborative, shared operational culture first, since team agility matters far more than heavy platforms.
Organizational Stage Primary Operational Focus
+-----------------------+ +-----------------------------------+
| Early-stage Startup | --> | Collaborative Shared Culture |
+-----------------------+ +-----------------------------------+
| Scaling Enterprise | --> | Standardized Developer Platforms |
+-----------------------+ +-----------------------------------+
However, as an organization scales up to employ hundreds of independent developers, building a standardized internal developer platform becomes absolutely critical. This platform prevents individual teams from wasting valuable time rebuilding custom infrastructure setups from scratch, ensuring widespread organizational alignment.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software enterprises utilize real-time operational data to drive massive business choices and protect their market positions. These technical leaders compile thousands of data points into centralized business dashboards that track system reliability alongside real-time revenue performance.
If a critical user path displays a sudden latency spike, automated financial systems instantly compute the projected impact on customer checkout drop-offs. This tight integration of technical metrics and business logic allows corporate leaders to make smart, data-driven decisions that safeguard digital profits.
Chaos Engineering Approaches to Resilient Systems
Highly advanced technology organizations deliberately inject controlled failures directly into their live production environments to uncover hidden infrastructure flaws before customers notice them. For instance, teams execute specialized automation programs that randomly terminate healthy virtual servers or simulate severe network delays during peak business hours.
[Inject Controlled Failure] --> [Observe System Response] --> [Fix Hidden Flaws Automatically]
This proactive practice forces software applications to fail gracefully by instantly shifting traffic over to surviving database instances across different regions. By intentionally breaking their own systems under controlled conditions, engineers can build incredibly robust platforms that handle real disasters effortlessly.
Handling Reliability at Massive Scale
Orchestrating reliable digital environments for millions of global users requires migrating away from fragile monolithic applications toward decentralized microservice architectures. These complex distributed systems utilize intelligent load balancers that automatically scatter incoming traffic across thousands of isolated software containers globally.
If a single backend microservice experiences an internal crash, the surrounding infrastructure automatically isolates the broken component while leaving the rest of the application fully functional. This modular isolation ensures that a failure in a minor background system never brings down your entire customer-facing application.
High-Availability in Fintech Operations
Financial technology platforms operate under strict government regulations and zero-tolerance expectations regarding system downtime, data corruption, or transaction delays. To meet these high security standards, fintech operations engineers deploy multi-region active-active database infrastructures that synchronize banking transactions across geographic zones instantly.
Every single database transaction undergoes cryptographic validation, automated security inspection, and real-time fraud monitoring before getting permanently committed to the digital ledger. This ultra-secure architecture allows modern financial platforms to process billions of dollars safely while maintaining round-the-clock service availability.
Scaled-Down but Essential Systems for Startups
Early-stage startup companies often operate with very small engineering squads and tight budgets, making massive enterprise infrastructure platforms entirely impractical. Fortunately, tiny teams can apply these core operational principles highly efficiently by leaning heavily on managed cloud services and serverless computing.
By utilizing managed database clusters and automated continuous deployment engines, a small startup can achieve great system observability without manual maintenance overhead. This smart approach allows early-stage companies to keep operational costs low while building an excellent foundation for future scaling.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A highly damaging mistake made by legacy engineering organizations is treating modern systems infrastructure specialists as an outsourced, round-the-clock emergency support desk. When management simply forces engineers to sit by their laptops waiting to resolve recurring server alerts, systemic architectural issues never get fixed.
True operational engineering requires dedicating more than half of your team’s time to proactive software development and structural optimization tasks. If your technical staff spends all their working hours responding to urgent pages, you are running a traditional operations center under a trendy new name.
Mistake 2 — Setting Unrealistic SLOs
Many ambitious business executives and product managers instinctively demand perfect 100% system availability targets for their digital software products without evaluating the trade-offs. Demanding absolute perfection sounds great in corporate meetings, but it creates a massive engineering roadblock that completely stalls software innovation velocity.
Chasing unrealistic uptimes forces your development squads to slow down feature releases dramatically out of intense fear of draining the error budget. Furthermore, the extreme infrastructure costs required to build additional layers of physical redundancy will quickly destroy your technology profit margins.
Mistake 3 — Ignoring Toil Until It’s Too Late
When an organization fails to prioritize identifying and automating away repetitive manual chores, a massive amount of operational debt accumulates silently over time. As your business grows, these manual tasks expand exponentially until they occupy the entire working week of your engineering department.
Manual Chores Multiply --> Engineers Burn Out --> Innovation Velocity Stops Completely
Your technical specialists quickly become exhausted, leading to critical configuration mistakes, dropped balls, and widespread career burnout that decimates team retention. Ignoring this administrative drag eventually blocks all development progress, trapping your entire engineering department in an expensive cycle of basic system maintenance.
Mistake 4 — Skipping Blameless Postmortems
When a technology department operates with a toxic culture of blame, engineers instinctively hide operational mistakes, manipulate monitoring data, and avoid taking creative risks. If a postmortem meeting turns into an interrogation to find out who made a mistake, the true structural causes remain unaddressed.
Skipping or sabotaging these postmortem reviews guarantees that the exact same technical failure will happen again in the future. Organizations must realize that human errors are merely symptoms of underlying system flaws, which can only be uncovered through open, honest communication.
Mistake 5 — Monitoring Without Actionable Alerts
Setting up hundreds of complex monitoring dashboards that broadcast flashing red alerts for minor, non-critical background events creates a dangerous environment of alert fatigue. When an engineer’s phone triggers dozens of loud push notifications every hour for harmless CPU spikes, they naturally start ignoring the alerts.
Harmless Alerts Flash Continuously --> Engineer Ignores Phone Notifications --> Real System Outage Missed
Eventually, a truly catastrophic system failure strikes your production environment, and the critical alert gets completely missed amidst the mountain of digital noise. Every single notification sent to an on-call engineer must require a specific, urgent human action; everything else belongs in a background report.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Many traditional enterprise organizations allow software development squads to architect complex application structures completely in isolation from the operations staff. Once the software is written, developers simply hand it off over the wall to the operations team to run and maintain in production.
This outdated practice introduces massive deployment risks, as software developers often fail to anticipate real-world cloud networking limits or data scaling bottlenecks. Operational engineering specialists must sit actively at the design table from day one to ensure that every new system is built for long-term reliability.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Building a highly responsive, modern observability pipeline requires deploying an interconnected stack of specialized open-source tools and enterprise software solutions. Teams leverage high-performance time-series databases like Prometheus to collect deep system metrics from thousands of active server nodes every few seconds.
These rich performance metrics are pulled into advanced data visualization platforms like Grafana, creating clear dashboards that help teams spot trends at a glance. For comprehensive application tracking, enterprises integrate comprehensive observability suites like Datadog and New Relic to monitor software code performance in real-time.
Incident Management
When critical production incidents strike your enterprise cloud, teams rely on dedicated response platforms like PagerDuty to manage communication and speed up remediation. These intelligent alerting engines ingest incoming data signals from monitoring systems, instantly filter out redundant noise, and route urgent notifications to the correct on-call engineer.
The platform manages complex escalation paths automatically, ensuring that if the primary engineer fails to respond within ten minutes, a secondary specialist gets alerted. This automated coordination helps distributed engineering teams assemble rapidly, document incident timelines cleanly, and drive down your average time to system resolution.
CI/CD & Release Engineering
Modern continuous integration and deployment platforms act as the central automated engineering backbone for delivering reliable, predictable software infrastructure updates. Automation engines like Jenkins handle the heavy lifting of pulling raw application code, running unit tests, and compiling secure software packages.
+--------------+ +---------------+ +--------------+ +--------------------+
| Code Commit | ---> | Jenkins Test | ---> | Argo CD Git | ---> | Spinnaker Regional |
| (Developer) | | & Compile | | Sync State | | Canary Deploy |
+--------------+ +---------------+ +--------------+ +--------------------+
Once the code is thoroughly verified, declarative GitOps deployment engines like Argo CD automatically synchronize the desired system configuration state with live Kubernetes clusters. To safely orchestrate multi-region software deployments, enterprises use robust platforms like Spinnaker to manage progressive canary releases and automated rollbacks.
Chaos Engineering
To systematically uncover hidden architectural flaws inside production ecosystems, engineering departments deploy specialized chaos engineering software designed to inject controlled failures. Automation frameworks like Chaos Monkey run continuously in background environments, randomly destroying virtual machine instances or severing network paths without warning.
These controlled disruptions force engineers to design highly resilient software applications that can seamlessly withstand sudden hardware losses without dropping active user sessions. Using these advanced failure-injection platforms helps organizations move away from a defensive mindset and transition into a state of continuous operational confidence.
SLO Management
As modern enterprise tracking matures, utilizing dedicated Service Level Objective management tools like Nobl9 becomes absolutely essential for guiding business choices. These specialized platforms hook directly into your existing monitoring tools to continuously calculate real-time error budget consumption against defined targets.
The software automatically generates clear alerts whenever an infrastructure team burns through their permissible error budget too quickly over a given month. Providing this transparent, data-driven visibility helps product owners and engineering directors make highly collaborative choices regarding when to prioritize stability over new feature creation.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Launching a successful professional career in modern systems infrastructure management requires mastering a highly diverse, cross-functional set of technical and communicative skills. Aspiring specialists must start by building a rock-solid comfort level with the Linux operating system command terminal and standard bash scripting utilities.
- Linux Systems Engineering: Mastering the terminal commands, file systems, process isolation models, and fundamental networking concepts inside Linux environments.
- Infrastructure Scripting: Developing a high level of proficiency with scripting languages like Python and Go to build custom internal automation utilities.
- Cloud Orchestration: Understanding the core infrastructure patterns of major public cloud hyperscalers, including virtual networking, storage blocks, and compute scaling.
- Container Management: Building a deep, practical understanding of containerization frameworks like Docker and cluster orchestration platforms like Kubernetes.
The Professional Learning Path
The journey toward senior infrastructure expertise begins with learning to manage single application server deployments manually before progressing to wide-scale automation. Next, engineers learn to express infrastructure requirements purely as written code blocks using modern declarative template engines.
[Level 1: Manual Server Setup] --> [Level 2: Infrastructure as Code] --> [Level 3: Multi-Region Architecture]
From there, you learn to build automated continuous integration and continuous deployment pipelines that move software configurations safely through staging and production. Finally, advanced engineers step up to architecting multi-region, self-healing cloud networks that incorporate deep observability data and financial guardrails.
Certifications Worth Pursuing
Earning respected, industry-recognized professional technical certifications is an excellent way to validate your real-world cloud infrastructure skills to prospective global employers. Aspiring systems experts should prioritize pursuing the Certified Kubernetes Application Developer (CKAD) and Certified Kubernetes Administrator (CKA) credentials to prove container orchestration expertise.
Additionally, earning networking credentials like the CCNA provides a fantastic foundation in fundamental routing and switching protocols. Rounding out your portfolio with specialized foundation paths, such as the SRE Foundation or automated testing engineering paths, will ensure your technical skills stand out.
Educational Resources with Xopsschool
Navigating this massive learning path completely alone can feel incredibly overwhelming, given the vast number of fast-moving infrastructure technologies across the industry. Fortunately, aspiring engineers can fast-track their professional growth by enrolling in the highly structured, mentor-led educational courses at Xopsschool.
The comprehensive training tracks deliver a brilliant mix of deep architectural theory, real-world case studies, and extensive hands-on lab environments. Learning under the direct guidance of veteran systems experts allows you to build the exact technical competencies required to lead large-scale digital transformations.
The Future of Systems Management
AI and Automation in System Optimization
Looking ahead, the widespread integration of advanced machine learning algorithms is completely reshaping how global enterprises manage and secure their digital platforms. Next-generation artificial intelligence engines can continuously scan millions of incoming infrastructure telemetry points in real-time to isolate subtle system anomalies.
These smart systems can automatically predict impending database crashes, discover hidden network bottlenecks, and suggest precise optimization adjustments before a human engineer notices. Leveraging machine intelligence allows technology teams to dramatically speed up complex root-cause analyses and transition from proactive engineering into predictive remediation.
Platform Engineering — The Evolution of Infrastructure
The rapid expansion of internal platform engineering represents a massive shift in how scaling enterprises structure their internal software development workflows. Rather than forcing every developer to navigate complex low-level cloud configurations, dedicated tool teams build centralized internal self-service developer portals.
+--------------------------------------------------------+
| Internal Developer Portal |
| [Click to Deploy: Clean App Environment instantly] |
+--------------------------------------------------------+
|| (Automated Orchestration)
\/
+--------------------------------------------------------+
| Complex Multi-Cloud & Kubernetes Infrastructure |
+--------------------------------------------------------+
These portals offer pre-configured, fully compliant “golden paths” that allow software developers to deploy clean, secure application environments with a single click. This smart architecture protects corporate governance standards while empowering software development squads to move faster without manual infrastructure friction.
Management in Cloud-Native & Kubernetes Environments
As global organizations shift entirely toward complex cloud-native architectures, orchestrating large-scale Kubernetes environments presents highly unique operational and security challenges. Managing thousands of dynamic, ephemeral software containers requires building automated service meshes that handle internal service communication safely.
Engineers face the complex task of enforcing strict security controls, balancing cluster resources, and ensuring cross-region storage synchronization across fluid environments. Developing specialized skills in container storage patterns and dynamic cluster scaling will remain a massive competitive advantage for future systems architects.
Operational Skills That Will Matter Most
In the coming era of distributed cloud systems, the most successful infrastructure experts will be those who can connect technical metrics with corporate financial data. As cloud spending continues to rise globally, organizations will prioritize hiring engineering professionals who understand how to optimize system performance for maximum cost efficiency.
Mastering advanced data tracing techniques, distributed cloud cost tracking, and modern green-computing optimization practices will become absolutely essential for tech career growth. The future belongs to multi-dimensional systems experts who can confidently deliver ultra-reliable application environments while keeping corporate financial budgets completely lean.
FAQ Section
- What is the typical career path for an infrastructure expert?Most technical professionals launch their career journeys as junior software developers, systems administrators, or network engineers before transitioning into specialized infrastructure optimization roles. With experience, they advance into senior architectural positions, principal infrastructure consulting, or corporate technology leadership paths.
- How do these modern strategies directly reduce enterprise cloud spending?These frameworks combine real-time system performance monitoring with financial tracking data to eliminate wasteful over-provisioning across your cloud environments. Automated scaling systems dynamically adjust server footprint based on user traffic demands, ensuring you only pay for resources when they are actively needed.
- What are the most critical metrics for measuring system health?Engineering teams track system health by tracing the four golden signals: latency, traffic, errors, and saturation. Monitoring these metrics across your infrastructure pipeline allows you to detect performance drops and fix structural bottlenecks before they impact your customers.
- Is it necessary to learn programming to work in this field?Yes, having a strong comfort level with software programming and scripting languages like Python or Go is absolutely essential for modern systems engineering. Writing custom automation scripts is the primary way that modern infrastructure professionals eliminate repetitive manual chores and scale systems efficiently.
- What is the core difference between an SLA and an SLO?A Service Level Agreement is a formal legal contract that outlines financial or legal penalties if system performance drops below an agreed mark for external customers. A Service Level Objective is an internal target metric that guides daily engineering priorities and balances development speed with baseline system stability.
- How does a blameless corporate culture improve overall system reliability?A blameless culture encourages engineers to speak openly and honestly about production failures without fear of personal punishment or professional retaliation. This open communication allows teams to run detailed root-cause investigations that permanently fix underlying system flaws rather than hiding mistakes.
Final Summary
Building a highly successful, modern enterprise technology infrastructure requires a profound cultural commitment to continuous automation, deep system observability, and proactive engineering discipline. Organizations can eliminate stressful fire-fighting emergencies by establishing clear Service Level Objectives, tracking error budgets, and systematically engineering away manual chores. Embracing this holistic operational framework empowers your engineering squads to balance rapid software innovation with rock-solid production stability, protecting your user experience and optimizing corporate spending. As global cloud architectures grow increasingly complex, investing in your team’s technical education and mastering advanced optimization frameworks at Xopsschool will remain the ultimate key to driving sustained digital business success.