Introduction
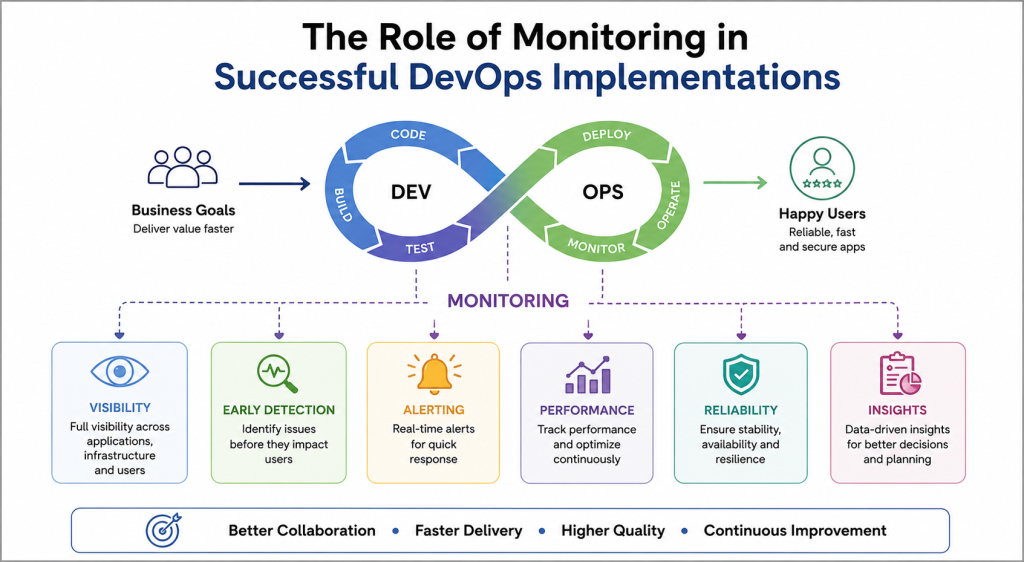
Modern software systems operate in highly dynamic environments where applications, infrastructure, networks, and services continuously change. As organizations adopt DevOps practices, they focus on delivering software faster while maintaining stability, security, and performance. However, speed alone does not guarantee success. Teams need visibility into every layer of their technology stack so they can identify issues before they impact users. This is where monitoring becomes a critical component of DevOps.
Monitoring provides real-time insights into application behavior, infrastructure health, user experience, and operational efficiency. It helps teams detect anomalies, reduce downtime, improve reliability, and make informed decisions. Organizations that implement strong monitoring practices can respond quickly to incidents and continuously improve their systems.
Many organizations strengthen their operational capabilities through professional learning platforms such as Xopsschool, where technology professionals gain practical knowledge about modern operations, automation, monitoring, and DevOps practices. Effective monitoring enables teams to move from reactive problem-solving to proactive operational excellence, making it one of the most important pillars of successful DevOps implementations.
Why Monitoring Matters in DevOps
DevOps focuses on collaboration, automation, continuous integration, continuous delivery, and rapid feedback. Monitoring plays a central role in creating that feedback loop. Without monitoring, teams cannot understand how applications behave in production environments. They may deploy new features quickly, but they will struggle to identify performance bottlenecks, infrastructure failures, or user experience issues.
Monitoring allows teams to measure system health continuously. Instead of waiting for customers to report problems, engineers can detect issues early through metrics, logs, traces, and alerts. This proactive approach reduces downtime and helps organizations maintain service reliability. Monitoring also provides valuable operational intelligence that supports capacity planning, resource optimization, and performance improvement initiatives.
As DevOps teams embrace frequent deployments, the importance of monitoring increases significantly. Each release introduces changes that can affect system behavior. Monitoring ensures that teams can evaluate the impact of these changes immediately and take corrective actions when necessary.
Monitoring as the Foundation of Reliability
Reliability is one of the primary goals of any operational environment. Users expect applications to remain available, responsive, and secure regardless of workload fluctuations. Monitoring helps organizations achieve these expectations by providing continuous visibility into system performance and operational health.
When engineers monitor infrastructure, applications, databases, and networks, they gain a complete understanding of system behavior. They can identify patterns, detect unusual activity, and recognize early warning signs before failures occur. This capability significantly reduces operational risk.
Reliable systems depend on accurate information. Monitoring collects and analyzes operational data that helps teams understand resource utilization, response times, error rates, and service dependencies. These insights support informed decision-making and enable teams to improve system stability over time.
Organizations that prioritize monitoring often experience fewer service interruptions, faster recovery times, and higher customer satisfaction because they can identify and resolve issues before they become major incidents.
Key Benefits of Monitoring in DevOps
Monitoring delivers numerous advantages that directly support DevOps objectives. One of the most important benefits is faster incident detection. Instead of discovering problems through customer complaints, teams receive immediate alerts when performance metrics exceed defined thresholds.
Another major benefit is improved operational visibility. Monitoring provides a centralized view of system performance across multiple environments, making it easier to understand dependencies and identify root causes. Teams can quickly determine whether issues originate from applications, infrastructure, databases, or external services.
Monitoring also supports continuous improvement. By analyzing historical performance data, teams can identify trends and optimize resource utilization. Additionally, monitoring helps organizations improve deployment confidence because engineers can evaluate system behavior immediately after releasing new features.
Furthermore, monitoring contributes to better collaboration among development, operations, security, and management teams by providing a shared source of operational truth that supports informed discussions and decision-making.
Key Operational Concepts You Must Know
Understanding operational concepts is essential for building effective monitoring strategies. One of the most important concepts is observability. Observability goes beyond traditional monitoring by helping teams understand internal system behavior through metrics, logs, and traces. It enables engineers to investigate complex issues and uncover hidden performance bottlenecks.
Another critical concept is service level objectives. These objectives define measurable performance targets that help teams maintain service quality. Monitoring tools track these objectives and notify teams when performance deviates from expected levels.
Incident management is equally important. Monitoring systems generate alerts when anomalies occur, but teams must also establish processes for investigation, escalation, and resolution. Capacity planning represents another key concept. By analyzing monitoring data, organizations can predict future resource requirements and avoid performance degradation caused by insufficient infrastructure.
Root cause analysis, performance optimization, automation, and reliability engineering are additional operational concepts that work closely with monitoring to create resilient and efficient technology environments.
Understanding Metrics, Logs, and Traces
Metrics, logs, and traces form the foundation of modern monitoring systems. Metrics provide numerical measurements that describe system performance over time. Examples include CPU utilization, memory consumption, request rates, response times, and error percentages. These measurements help teams identify trends and detect anomalies quickly.
Logs capture detailed records of system events and application activities. They provide context that helps engineers understand what happened during specific incidents. Log analysis often reveals configuration issues, security events, and application errors that metrics alone cannot explain.
Traces track requests as they move through distributed systems. Modern applications frequently involve multiple services communicating with each other. Tracing allows teams to visualize these interactions and identify delays or failures within complex workflows. Together, metrics, logs, and traces provide comprehensive operational visibility and support effective troubleshooting efforts.
Building Effective Alerting Strategies
Monitoring data becomes valuable when it supports timely action. Alerting systems transform operational information into actionable notifications that help teams respond quickly to potential issues. However, effective alerting requires careful planning and configuration.
Many organizations struggle with alert fatigue because they generate excessive notifications that overwhelm engineers. Effective alerting focuses on meaningful events that require attention. Teams should define clear thresholds based on business requirements and service objectives rather than creating alerts for every minor fluctuation.
Alert prioritization is equally important. Critical issues affecting customer experience should receive immediate attention, while less urgent concerns can follow standard response procedures. Organizations should also continuously review alert effectiveness and eliminate notifications that do not provide operational value.
A well-designed alerting strategy helps teams maintain focus, improve response times, and reduce unnecessary operational noise.
Platform Implementation vs. Culture — What’s the Real Difference?
Organizations often invest heavily in monitoring platforms, dashboards, and automation tools while overlooking the cultural aspects of DevOps. Although technology platforms provide essential capabilities, culture ultimately determines whether those capabilities create meaningful outcomes.
Platform implementation focuses on deploying tools, configuring monitoring systems, collecting data, and building operational workflows. These technical activities are necessary because they establish the foundation for visibility and operational control. However, tools alone cannot guarantee success.
Culture emphasizes collaboration, accountability, learning, and continuous improvement. Teams must actively use monitoring insights to drive better decisions and improve operational practices. When engineers treat monitoring as a shared responsibility, they become more proactive in identifying and addressing issues.
The real difference lies in behavior. Platforms provide information, while culture determines how people use that information. Successful DevOps organizations combine strong monitoring technology with a culture that values transparency, ownership, and continuous learning.
Creating a Monitoring-Driven Culture
A monitoring-driven culture encourages teams to rely on data rather than assumptions. Engineers use operational insights to evaluate system performance, investigate incidents, and improve reliability. This approach creates a more objective and collaborative environment.
Leadership plays an important role in fostering this culture. Managers should encourage teams to analyze monitoring data regularly and discuss operational findings during planning and review sessions. Monitoring should not be limited to operations teams. Developers, testers, security professionals, and business stakeholders should also understand relevant metrics and performance indicators.
Organizations that embrace monitoring-driven decision-making often experience faster problem resolution and better alignment between technical and business objectives. Over time, teams become more confident because they have access to accurate operational information that supports informed actions.
Real-World Use Cases of Modern Operations
Modern operations teams use monitoring across a wide range of scenarios. One common use case involves application performance management. Teams monitor response times, transaction success rates, and user interactions to ensure applications deliver consistent experiences.
Another important use case focuses on infrastructure health monitoring. Engineers track server performance, storage utilization, network activity, and resource availability to prevent outages and maintain operational stability. Monitoring also supports cloud operations by providing visibility into dynamic environments where resources scale automatically based on demand.
Security monitoring represents another critical application. Teams analyze logs and system activity to identify suspicious behavior and potential threats. Additionally, monitoring supports business intelligence by helping organizations understand user behavior, service adoption, and operational efficiency.
These real-world applications demonstrate how monitoring contributes to reliability, security, performance, and business success across modern technology environments.
Monitoring in Continuous Delivery Pipelines
Continuous delivery enables organizations to release software rapidly and consistently. However, frequent deployments increase operational complexity and create additional risks. Monitoring helps teams manage these challenges effectively.
During deployments, monitoring systems track application behavior and performance indicators in real time. Engineers can quickly identify issues introduced by new releases and take corrective action before customers experience significant impact. Monitoring also supports deployment validation by confirming that services continue to meet performance expectations after updates.
Advanced organizations integrate monitoring directly into delivery pipelines. Automated checks evaluate key metrics during deployment processes and prevent releases from progressing when performance degrades beyond acceptable limits. This integration strengthens quality assurance and reduces operational risk while maintaining deployment speed.
Monitoring therefore becomes an essential safeguard that supports reliable and efficient continuous delivery practices.
Common Mistakes in Operations Engineering
Many organizations invest in monitoring solutions but fail to achieve the expected results because of common operational mistakes. One frequent mistake involves monitoring too many metrics without defining clear objectives. Excessive data collection can create confusion and make it difficult to identify meaningful insights.
Another common issue is relying solely on infrastructure monitoring while ignoring application-level visibility. Infrastructure metrics provide valuable information, but they do not always reveal how users experience services. Teams should monitor both technical performance and user-facing outcomes.
Poor alert management also creates challenges. Excessive notifications can overwhelm engineers and reduce response effectiveness. Additionally, some organizations fail to review monitoring data regularly, causing valuable insights to remain unused.
Another mistake involves treating monitoring as an operations-only responsibility. Successful DevOps environments encourage shared ownership across development, operations, security, and management teams. Avoiding these mistakes helps organizations maximize the value of monitoring investments.
Best Practices for Monitoring Success
Organizations can improve monitoring outcomes by following several proven practices. First, define clear monitoring objectives that align with business goals and service expectations. Teams should understand exactly what they need to measure and why those measurements matter.
Second, establish comprehensive visibility across applications, infrastructure, networks, and user experiences. Integrated monitoring provides a complete understanding of system behavior and simplifies troubleshooting efforts. Third, automate data collection and alert generation whenever possible to improve efficiency and consistency.
Regular review processes are equally important. Teams should analyze monitoring results, evaluate trends, and identify opportunities for optimization. Documentation and knowledge sharing also strengthen monitoring effectiveness because they help teams respond more efficiently during incidents.
Finally, organizations should continuously refine monitoring strategies as systems evolve. Effective monitoring requires ongoing improvement rather than a one-time implementation effort.
How to Become an Operations Expert — Career Roadmap
Building expertise in operations requires a combination of technical knowledge, practical experience, and continuous learning. Beginners should start by understanding operating systems, networking fundamentals, cloud platforms, and infrastructure concepts. These foundational skills provide the technical background necessary for modern operations roles.
After establishing core knowledge, professionals should learn monitoring technologies, logging systems, automation tools, and incident management practices. Hands-on experience is essential because operational skills develop through real-world problem-solving. Engineers should actively participate in troubleshooting activities, performance analysis, and reliability improvement initiatives.
A successful operations expert typically develops expertise in several key areas:
- System administration
- Cloud infrastructure
- Monitoring and observability
- Automation and scripting
- Incident response
- Performance optimization
- Reliability engineering
- Security fundamentals
Continuous learning remains critical throughout the journey. Technology environments evolve rapidly, and successful professionals consistently expand their knowledge to stay relevant and effective.
Operations Career Roles and Responsibilities
| Role | Primary Focus |
|---|---|
| Operations Engineer | Infrastructure stability and performance |
| DevOps Engineer | Automation and delivery pipelines |
| Site Reliability Engineer | Reliability and scalability |
| Cloud Engineer | Cloud infrastructure management |
| Platform Engineer | Internal platform development |
| Monitoring Specialist | Observability and operational visibility |
| Systems Engineer | Enterprise system administration |
| Reliability Analyst | Service performance evaluation |
Each role benefits from strong monitoring knowledge because operational visibility supports decision-making, troubleshooting, and continuous improvement across technology environments.
FAQ Section
What is monitoring in DevOps?
Monitoring is the continuous observation of applications, infrastructure, networks, and services to identify performance issues, failures, and operational trends before they affect users.
Why is monitoring important for DevOps success?
Monitoring provides real-time feedback that helps teams maintain reliability, improve performance, reduce downtime, and support continuous delivery initiatives.
What is the difference between monitoring and observability?
Monitoring focuses on tracking predefined metrics and alerts, while observability helps teams understand complex system behavior through metrics, logs, and traces.
Which metrics should organizations monitor?
Organizations should monitor performance indicators such as response times, error rates, availability, resource utilization, transaction success rates, and user experience metrics.
How does monitoring improve incident response?
Monitoring enables early detection of issues, provides operational context, and helps engineers identify root causes more quickly, reducing recovery times.
Can small organizations benefit from monitoring?
Yes. Monitoring helps organizations of all sizes improve visibility, reliability, and operational efficiency while supporting future growth and scalability.
What role does monitoring play in continuous delivery?
Monitoring validates deployment outcomes, detects release-related issues, and helps teams maintain service quality during frequent software updates.
Is monitoring only the responsibility of operations teams?
No. Modern DevOps practices encourage shared responsibility, meaning developers, operations engineers, security teams, and stakeholders all benefit from monitoring insights.
Final Summary
Monitoring serves as one of the most important foundations of successful DevOps implementations. It provides the visibility required to understand system behavior, detect issues early, improve reliability, and support continuous improvement efforts. As organizations increase deployment frequency and operational complexity, monitoring becomes even more valuable because it enables proactive decision-making and faster incident response.
Effective monitoring combines metrics, logs, traces, alerting strategies, operational processes, and collaborative culture. While monitoring platforms provide technical capabilities, organizations achieve the greatest success when teams actively use operational insights to drive improvements and strengthen reliability. By understanding key operational concepts, avoiding common mistakes, adopting best practices, and continuously developing operational expertise, professionals can build resilient technology environments that support both business goals and customer expectations. Monitoring is not simply a toolset. It is a strategic capability that empowers organizations to deliver reliable, high-performing services with confidence.